Как невронните мрежи променят търсещите машини?

Невронните мрежи се превръщат в неизменна част от SEO оптимизацията в днешни дни. Като част от Machine Learning, те се утвърдиха като работещи модели и стъпка напред за по-добро разбиране на потребителските очаквания и намерения зад заявките за търсене в търсещите машини като Google.
Дани Съливан обяви преди около месец за въвеждането на тези мрежи и при търсенето на Гугъл. Основна идея на търсачката е създаване на алгоритми, които да не са зависими дотолкова от Information Retrieval алгоритмите.
Определят се като независими, на база на изцяло нова технология да преценяват релевантността на документ – спрямо фраза и обратното.
Класификация на значението на документа, известен също като adhoc, е задачата за класиране на документи от голяма колекция с помощта на заявка и само текста на всеки документ. Това контрастира със стандартните системи за извличане на информация (IR), които разчитат на текстови сигнали във връзка с мрежова структура и / или обратна връзка от потребителя.
Класирането на базата на текст е особено важно, когато i) информацията за кликванията на потребителите не съществува или е оскъдна, и ii) мрежовата структура на колекцията от документи е несъществуваща или неспецифична за фокусиране на значението върху заявките за търсене.
Какво е невронно свързане (neural matching)?
Покривайки 30% от заявките за търсене, алгоритъмът за съвпадение на нервите има за цел да съответства на заявките за търсене и на уеб страниците. Този метод свързва думи с концепции. Тъй като търсенето на глас изглежда е следващият начин за търсене през идните години, способността за по-добро разбиране на концепциите е важна за опита на потребителите на Google. Тук има нещо важно: този метод не разчита на сигнали за връзка. Все пак той използва страници, които вече са класирани на определени позиции.
Как точно работи?
И така, какво може да изпълнява този алгоритъм за невронно съвпадение? Как резултатите все още могат да бъдат от значение? Този метод е базиран на ad hoc извличането. Kласирането в документа (друго име, използвано за това поле) използва TF-IDF резултата и косинусовото сходство, за да съответстват на фразите в документите и нуждите, изразени в заявките за търсене.
Тъй като алгоритъмът за съвпадение на невроните използва само думи в заявките за търсене, за да съответства на концепции, ad hoc методът за извличане не е достатъчен. Това е мястото, където изкуственият интелект влиза в действие. Тук техниката на изкуствената интелигентност, без надзор, се използва, за да напредва в разбирането от думи към концепции.
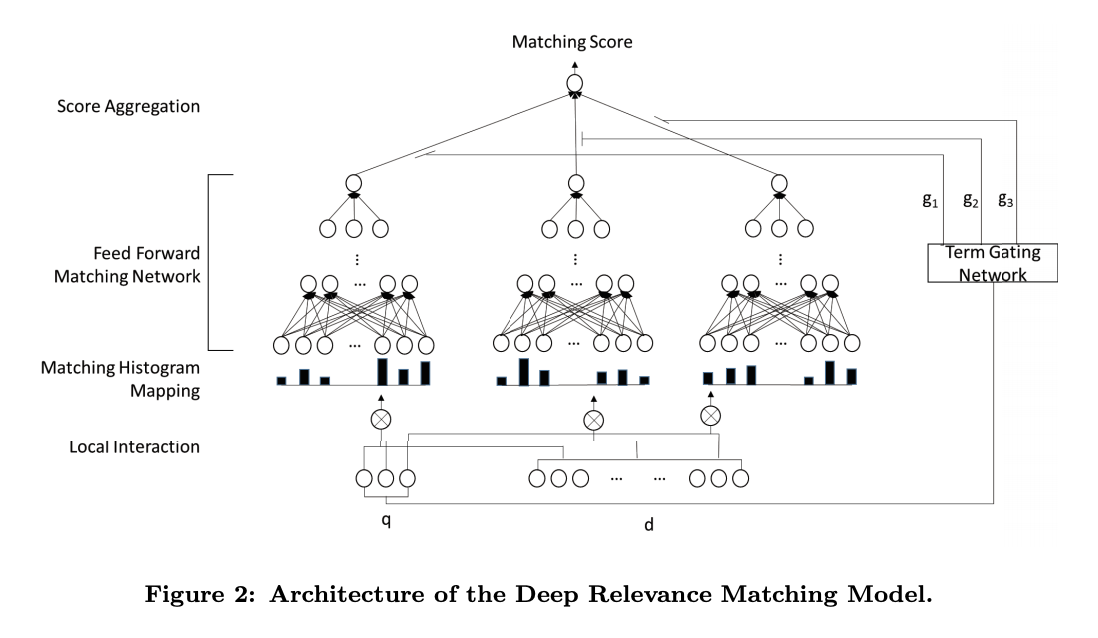
Подпомагана от модела за съвпадение на дълбокото съответствие (DRMM) за ad-hoc извличане, алгоритъмът за невронно съвпадение се основава на уместността. Този метод използва съвместна дълбока архитектура на ниво термини за заявки, над местните взаимодействия между заявките и документалните термини за съответствие на съответствието. За още по-дълбочинното решаване на проблема с релевантността инженерите създават и още един модел – AttentionBased ELement-wise DRMM, където се обръща внимание на тежестта на думите от заявка за търсене спрямо понятията, употребени в документа и приоритизирането им по важност.
За да може обаче документите в резултатите при търсене да бъдат подредени по степен на релевантност и качество, още 2 модела са създадени – POSIT-DRMM и Multiple Views of Terms (+MV). Двата модела сами по себе си могат да бъдат обекти на 2 отделни, детайлни статии със сложна и изклюитело техническа и математическа информация, но все пак ще ги обясним в следващите няколко реда.
Първият модел използва Max-Pooling и Average-Pooling калкулации, за да изчисли релевантността и връзката на думите във фразата и респективно цялата фраза както в максимална стойност, така и усреднено за по-голяма прецизност. Първата калкулация извежда най-силно силно свързаното понятие от дадена фраза спрямо документа, а средното подобие на всички понятия с връзка към съдържанието на документа.
И още малко по-дълбоко в моделите за релевантност и класиране
Контекстна-чувствителност при „разбиране“ на термините
По официална информация от Гугъл, търсачката използва два доста важни модела DRRM и PACRR, над които софтуерните инженери на Гугъл са надградили и създали собствени модели за релевантност и класиране.
Първият модел – DRRM се базира на връзката между заявката (или думи от заявката) спрямо думите използвани в документа, но не обръща внимание на реда, по който са подредени думите в заявката, както и на семантичната /смислова/ връзка между тях, както и евентуалната множествена връзка между тези думи. Моделът има слаба чувствителност и към дължината на фразата също.
Вторият модел – PACRR се базира на създаването на матрица, при която се изчислява косинусовата близост между думите в дадена заявка и думите, използвани в съдържанието на даден документ. Основното предимство спрямо предния модел е, че този взима под внимание редът на думите в дадена заявка за търсене, изчислява релевантността на база на n-gram конволуции, обръща се внимание на връзката с n-gram връзките на ниво плътност.
Как Google решават проблема с реалната семантична /смислова/ връзка между думите в заявките за търсене и тези в съдържанието на документа?
Инженерите на Гугъл обединяват двата модела и ги подобряват. В новосъздадения модел вече обръща внимание на думите в дадена заявка поотделно като важност в определяне на релевантността спрямо думите в съдържанието на даден документ. Създава се и модел за енкодиране на контекста между понятията в заявката.
Така докато първите 2 модела нямат чувствителност към контекста на думите в документите и заявките, то при този нов модел, наречен Context-sensitive Term Encodings се използват основните практики от Information retrieval, а именно близост на фразите, зависимост между тях, както и n-gram-и и заобикалящите ги фрази, особено когато трябва да се прецени връзката при множество заявки за търсене и употребени фрази в документ.
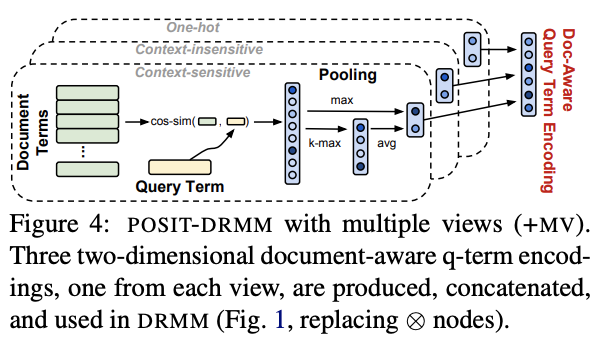
На финала, инженерите решават да разглеждат понятията във фразите и документите от различни ъгли. Затова и наричат този вотир модел Multiple Views of Terms (+MV). При него POSIT-DRMM създава двуизмерен document-aware encoding за всяко понятие от дадена фраза на търсене, разглежда се контекстът на семантичния смисъл между думите. При следващия двуизмерен изглед се разглежда директната връзка между думите във фразата за търсене и съдържанието на документа. Идва и трети изглед, където думите се разпределят по вектори и се разглеждат едновременно като директна връзка между думи в заявка и документ, спрямо тяхната семантична / смислова/ връзка. Или в крайна сметка получаваме 6-изгледен модел, който гарантира максимална релевантност на класираните документи, оформен в модел, наречен: POSIT-DRMM+MV
Какво означава това за SEO специалистите?
Тук, извън всички въпроси на изкуствената интелигентност, въпросът е дали този нов алгоритъм ще окаже влияние върху тези, които създават съдържание в уеб? Какви заявки се включват като част от 30%, които са обхванати от този нов алгоритъм? Знаем, че алгоритъмът RankBrain покрива около 15% от заявките за търсене, които никога не са били търсени преди.
Така или иначе влияние има – и то не малко, изкуственият интелект, както и machine learning в изучаването, класифицирането и категоризирането на текстове започва да играе все по-голяма и по-голяма роля. Ние в Серпакт също забелязваме ежедневно подобренията на Гугъл, както и някои проблеми, за които съобщаваме на екипа на търсещата машина регулярно.
Как ще интегрираме тази техника за съвпадение на съответствието (в съзвучие с другите рейтингови сигнали в този момент) в ежедневния ни работен процес? Отсега нататък SEO специалисти, които включват техники за обработка на естествен език в своя работен процес, трябва да се стремят към семантично съвпадение. Въпреки това, относителността от гледна точка на супер синоним (така наречена от Дани Съливан) все още може да изглежда като техника за спам, ако означава включване на синоними в съдържанието.
В момента все още не знаем достатъчно за целевите запитвания или за това как съдържанието трябва да бъде оптимизирано. Настоящото запазване на връзките – на базата на връзки между уебсайтове и санкциите за насищане със синоними може да попречи на неинформираните опити за оптимизиране за невронно съвпадение. Очевидно е обаче, че ще трябва да преосмислим как създаваме съдържание, за да се адаптираме.
Някои неща обаче са повече от сигурни по отношение на това какво Гугъл предпочита като текстове:
- Такива, които дават изключително добър отговор по дадена заявка, без значение от вида й
- Натурално написано съдържание
- Съдържание, което съдържа фрази, използвани в ежедневната онлайн реч от потенциалните потребители на продукт, услуга или информация
- Интерактивност на съдържанието
- Мултимедийност на съдържанието
- Съдържание изписано от хора, авторитети в индустриите
- Наличие на същности
- Наличие на тематичност и подтематичности
- Наличие на свързани фрази и тн.
За повече информация и сигурност, че съдържанието ви е семантично оптимизирано към момента, можете да потърсите екипа на Серпакт за анализ на съдържанието услуга, в която подробно ще ви разясним какво се случва със страниците ви и защо те класират или не класират толкова добре. Ще получите и препоръки как да ги подобрите.