Анализ на Google Патент: Свързани същности при търсене на фрази изискващи познание

Google патентите са едни от основните документи , чрез които търсачката представя и защитава по законен път технологиите , които интегрира в предоставяните си услуги . Едни от най-интересните , информативни и заслужаващи времето за четене, са патентите посветени на Google Search или казано по друг начин – какви алгоритми има заложени в Гугъл , така че да класира по релевантност резултатите по зададена заявка за търсене.
Въпреки спряганите 200 фактора за класиране на Гугъл, истината е, че те всъщност са над 3000. Макар и много популярни в дигиталния маркетинг специалисти да пишат, че ранкинг факторите са общи, такива всъщност няма, защото всяка фраза и всяко семантично ядро биха могли да имат собствени фактори, след въвеждане на RankBrain.
Какво точно прави Knowledge Graph?
В основата и сърцето на Гугъл е така нареченият Knowledge Graph, който най-общо може да се обясни като склад за трупане на знание, но не просто свързано с определени фрази, а намесващо се при тълкуване на фразите, които потребителите въвеждат при търсене. Това се случва като графът изучава в реално време същностите, които въвеждаме като част от заявките. Освен това негова основна цел е да дава отговор на въпрос към търсачката, точно както човек би го направил в хода на разговор с Вас.
През Януари 2018 година беше гарантиран патент от Google, според който търсачката придава оценка на свързаните същности при анализ на фрази, които включват такива същности и които изискват определено познание, което се извлича от Google Knowledge Graph и се представя под формата на резултати в Гугъл.
Ако трябва да разсъждаваме в малко по-голяма дълбочина, това означава, че SEO оптимизирането и работата с текстове се усложнява още повече, защото реално погледнато тук не става въпрос с обогатяването на текста с просто свързани думи, синоними и всякакви вариации на думи, а нещо много повече!
Доказателство за това е следният текст от патента:
In some implementations, a computer-implemented method comprises identifying in a knowledge graph, using at least one processor, at least one entity and related entities related to the at least one entity by respective properties. The computer-implemented method comprises, for each respective one of the related entities, determining, using at least one processor, a related entity score associated with a respective property that relates the at least one entity and the respective one of the related entities. The computer-implemented method comprises, for each respective property, generating a property score, using at least one processor, based on related entity scores associated with that respective property. The computer-implemented method comprises generating, using at least one processor, and causing to be stored a data structure of sortable properties based on the generated property scores, wherein the data structure is usable to provide sorted search results in response to a query.
 Какво представляват свързаните същности?
Какво представляват свързаните същности?
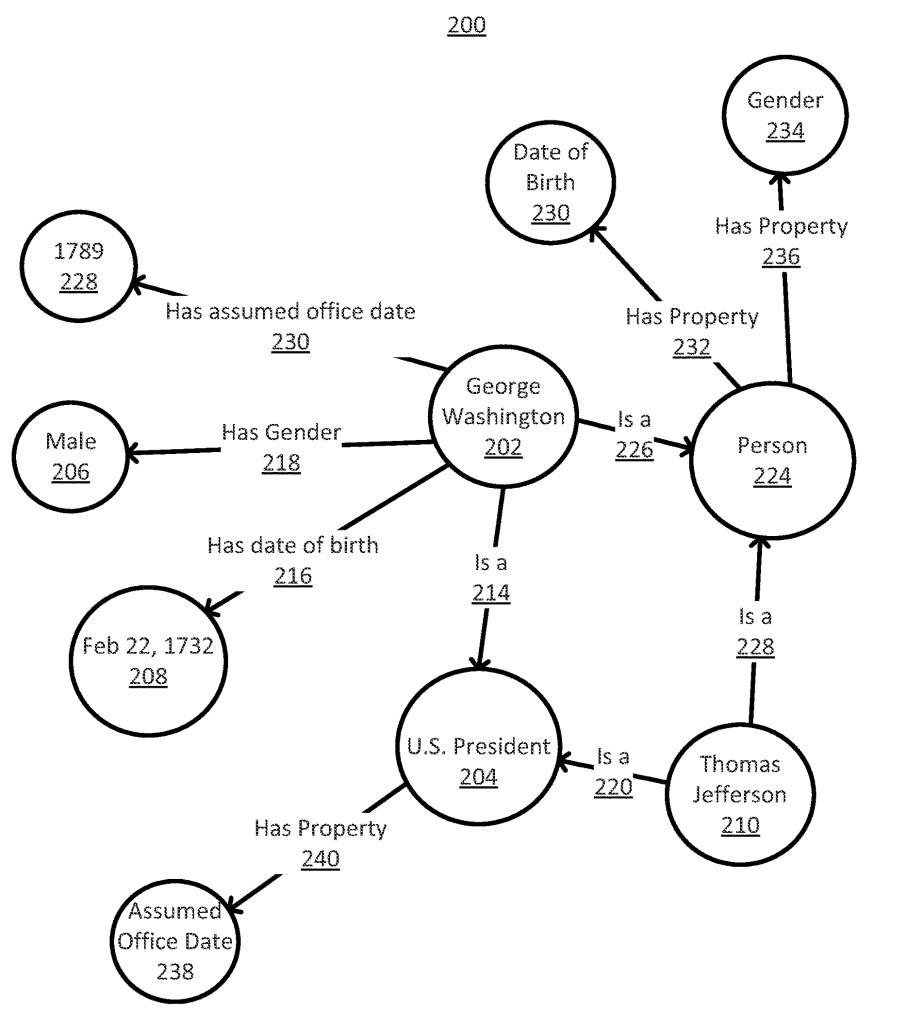 Какво представляват свързаните същности?
Какво представляват свързаните същности?Според обобщението на патента:
An entity may be related to multiple related entities by one or more properties, and the entity may also be associated with one or more entity types. A system for providing sorted results may include identifying the entity, related entities, and types. The system may also determine related entity scores for each respective related entity, relative to the entity.
For each property, the related entity scores of the related entities related to the entity by that property are combined to generate a property score. The properties are then sorted based on their property scores. The sorting may occur for properties associated with an entity type, and sorted search results may be provided as output for one or more entity types of interest.
Така в есенцията си патентът има за цел да ни информира и да подскаже, че Knowledge Graph-a вече е част от анализа на заявките за търсене в много сериозен аспект, особено когато задаваме въпрос на Гугъл. Дадена същност /обект, човек, локация, забележителност или просто нещо, което съществува или вече е дефинирано/, може и е свързано с множество други същности. Връзката между дадена същност и множеството от същности е базирано на едно или повече свойства. Тези същности могат да бъдат класифицирани и по типове и определена същност да бъде свързана и с определени типове обединени същности.
В случая в системата на Гугъл това така работи, че най-напред се идентифицира същността, след което се търсят свързаните с нея същности, както и видове същности. На тях им се придава и определена стойност, която колкото по-висока е, толкова по-семантично свързана е дадена същност към друга. За всяко свойство, стойностите на свързаните същности към определена същност по определено свойство се комбинират, за да образуват свойствена стойност на свързаност.
Свойствата, разбира се, след това се обединяват на база на свойствената стойност. Сортирането може да бъде и по свойства, свързани с определен тип същности и на база на тях подредени резултати в търсачката се появяват, на база на същността, която е обект на интерес.
Свързаните същности могат да бъдат и класирани в алгоритъма на Гугъл – Как точно става това?
Базирано на информация от друг патент (Related Entities) Google класира вътрешни същностите на база на:
- Колко често някой търси свързана същност, след като подаде заявка за първата същност.
- Колко популярна е свързаната същност в глобален аспект
- Колко често разпозната референция с информация за свързана същност, свързана към дадена същност се появява и във въведената заявка за търсене, като разпозната референция към оригиналната същност.
- Има ли информация, че 2 или повече свързани същности, част от втория тип същности са част от колекция от същности със специфичен ред – например, ако става дума за човек, който има деца и те са подредени, според датата им на раждане в информацията.
- Ако има информация, която е индикатор, че 2 или вече свързани същности са част от по-голяма същност, която е по-разпознаваема и тогава двете същности ще бъдат заменени от по-голямата същност.
Как това работи в България?
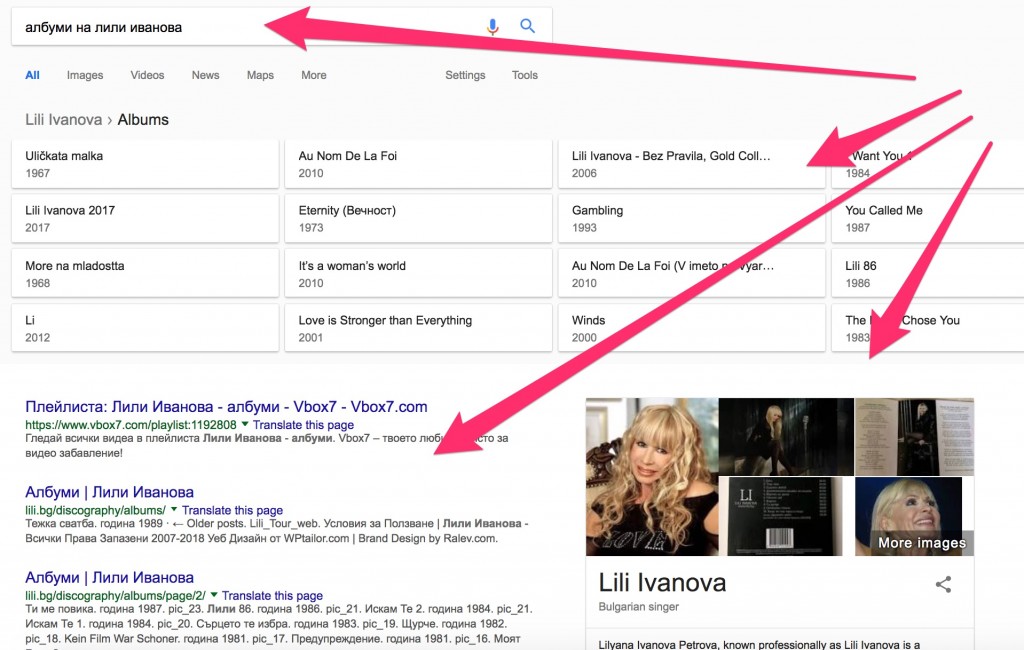
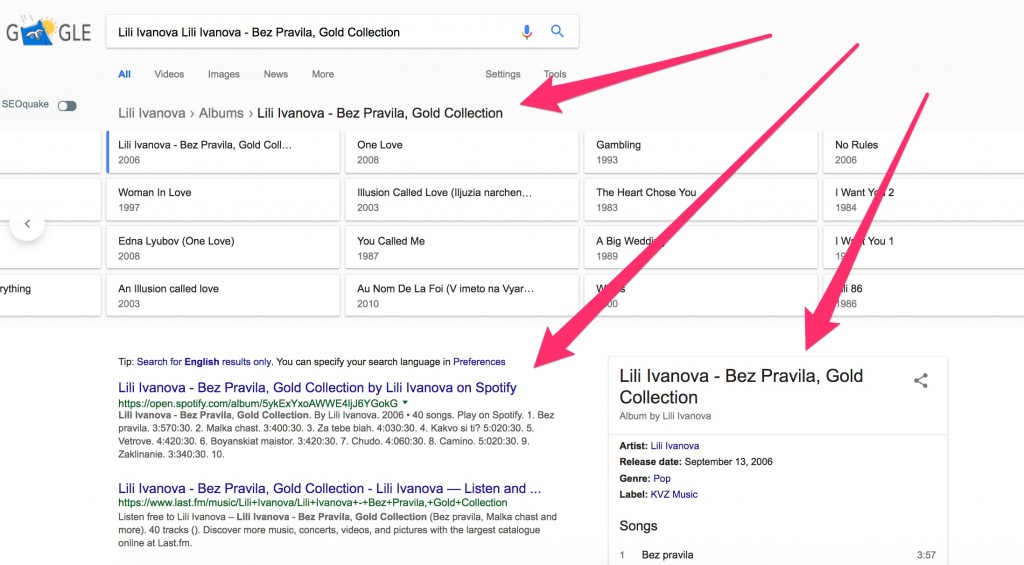
Ако въведем фразата „лили иванова албуми“, Гугъл извежда за нас резултат от Knowledge Graph в най-горната си част като първи елемент, за да ни даде директен достъп до албумите на певицата, на база на информацията, която е събрал от една страна чрез маркиране със структурна дата, както и на база въведените заявки в търсачката. Веднага след това е следващият елемент от Графа, в десния панел, с информация за личността Лили Иванова, а в органичните резултати, първи е vbox7, което е сигурен знак, че Графът не иска просто да ни предостави информация за четене, а разбира, че става дума за музика и иска да ни даде достъп и до музиката на примата.
Кликвайки на някой от резултатите с албумите, Графът ни води към информация за албума, което е поредно доказателство, че за да може Гугъл да предостави информация за нещо, то трябва да бъде същност, а това от своя страна означава предприемането на много тактики и действия. Едно от тях е задължителното маркиране със структурна дата.
Какво точно предствляват стойностите на свързаните същности?
 Съгласно патента на Гугъл:
Съгласно патента на Гугъл:
In some implementations, a system comprises a data structure comprising a knowledge graph, and one or more processors. The one or more processors are configured to perform operations comprising identifying in the knowledge graph at least one entity and related entities related to the at least one entity by respective properties. The one or more processors are configured to perform operations comprising, for each respective one of the related entities, determining a related entity score associated with a respective property that relates the at least one entity and the respective one of the related entities. The one or more processors are configured to perform operations comprising, for each respective property, generating a property score based on related entity scores associated with that respective property. The one or more processors are configured to perform operations comprising generating and causing to be stored a data structure of sortable properties based on the generated property scores, wherein the data structure is usable to provide sorted search results in response to a query.
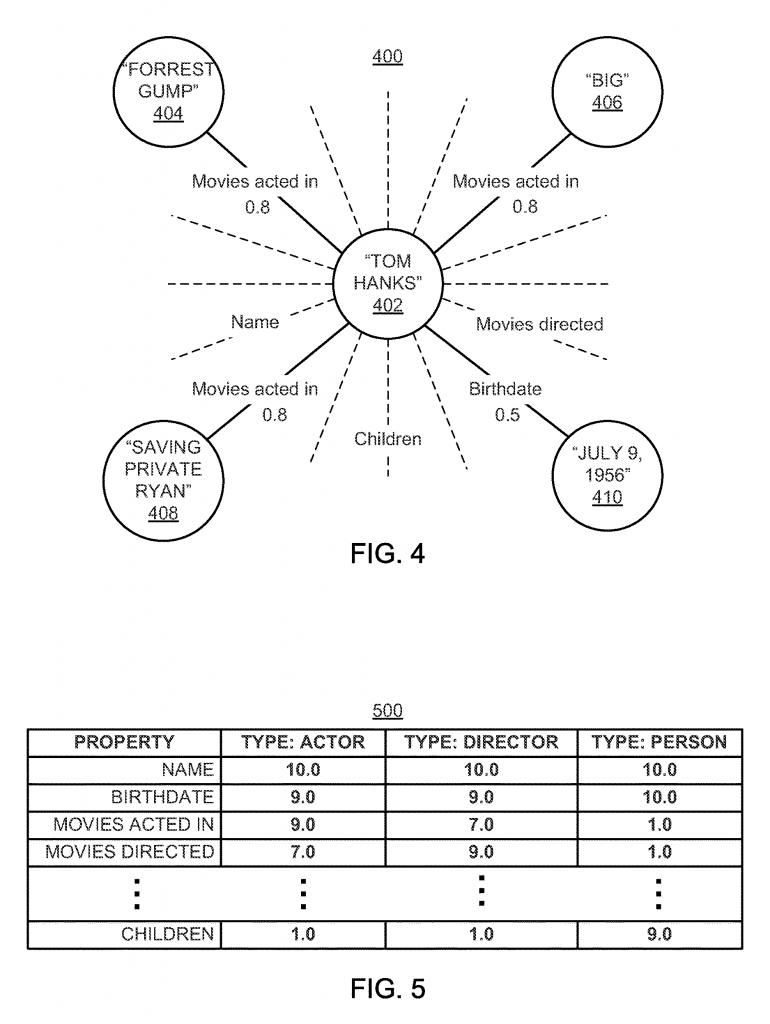
Related entity scores associated with each particular property may be combined for that property. For example, referencing FIG. 4, the related entity scores for related entities “Forrest Gump,” “Big,” and “Saving Private Ryan” may be summed to give a sum for the property “Movies acted in,” e.g., 0.8+0.8+0.8=2.4. In a further example, the related entity scores may be combined as a weighted sum. Any suitable combination of related entity scores may be used to generate the property score. In some implementations, one or more types may be a subtype of another entity type. For example, referencing data structure 550 of FIG. 5, the type “Actor” may be a subtype of the entity type “Person,” which may be referred to as a parent type relative to the subtype. In some such implementations, for the parent type, the property score for each property of each subtype may be summed with the same property of the parent type. For example, referencing data structure 550 of FIG. 5, property “Movies acted in” is included in type “Actor” and “Person,” and accordingly, the property score of 9.0 for the entity type “Actor” may be aggregated to the property score 1.0 for the entity type “Person.” The one or more processors may renormalize, scale, weight, or otherwise alter the scores within the parent type after incorporating the subtype.
С други думи, ако трябва да обобщим концепцията – то ще стигнем до следните изводи за това как точо работи технологията:
- 1 или 2 процесора, които изпълняват операции, целящи да разпознаят поне една същност от Графа на знанието,и свързана към нея същност, възоснова на определени свойства.
- 1 или 2 процесора изпълняват операции, целящи за всяка една от свързаните същности да се определи стойност на свързаността й, асоциирана с определено свойство, което се отнася до първоначалната същност, която споменахме като и свързаните с него същности.
- Използват се и 1-2 процесора в система, които изпълняват функции, целящи да дадат стойност на връзка на всяко свойство на база на стойността на връзката между свързаните същности, асоциирани с това свойство.
- Използват се и 1-2 процесора, които изпълняват функции, целящи да събират цялата информация в структура от данни, които да могат да бъдат сортирани и подреждани на база на генерираните стойности на свързаност, където от своя страна тези структури от данни се използват, за да дават подредени резултати при търсене на дадена фраза в Гугъл.
- Свързаните същности и техните стойности, асоциирани с определени свойства могат да бъдат обединени около тези свойства. Пример за това е фигура 4.
- В друг пример стойността на свързаност между свързаните същности може да бъде калкулирана като сума на тежест. Всяка допълнителна информация може да се използва и, за да се генерира стойността на свързаност и на свойствата.
- В някои случаи определени типове свързани същности могат да бъдат класифицирани в определен тип и да бъдат подтип на други типове същности. Доказателство за това е фигура 5, където “Actor” е подтип на “Person,” който може да бъде съотнесен като родителски тип, свързан с подтипа или на подтипа. При този случай стойността на свързаност между свойствата на всеки подтип може да бъде сумирана със същото свойство на главния, родителски тип. Пример: Ако погледнем таблицата от фигура 5, ще видим, че свойството “Movies acted in” е включено в типа “Actor” и “Person,” и съответно стойността на свързаност на свойството – 9.0 за същност тип “Actor” може да се агрегира със стойността на свързаност – 1.0 за същността тип “Person.”
 Или (ако трябва да съкратим още повече концепцията) то се извлича информация от Графа за конкретна същност, преглеждат се свързаните с нея същности на база на определено свойство и се придава стойност на свързаност както между същностите, така и между свойствата им и се проследяват връзките между свойства и същности в дълбочина.
Или (ако трябва да съкратим още повече концепцията) то се извлича информация от Графа за конкретна същност, преглеждат се свързаните с нея същности на база на определено свойство и се придава стойност на свързаност както между същностите, така и между свойствата им и се проследяват връзките между свойства и същности в дълбочина.
Мога ли сам да оптимизирам сайта си за Knowledge Graph и как Гугъл го използва?
Тук отговорът ще бъде кратък и той е- не, не можете, ако не познавате правилата на семантичното SEO. Има различни тактики за оптимизиране, но те са само основа. Необходимо е да познавате семантиката на Гугъл в дълбочина и да знаете къде точно да погледнете, за да успеете да извлечете полза от него.
Няма официално обявени тактики за правилното оптимизиране за Knowledge Graph и свързаните същности, освен добавянето на структурна дата разбира се и регистрация в сайтове, от които Гугъл агрегира информация.
Всъщност Гугъл вече използва не само определени сайтове, за да извлича информация, а множество на база фактори за качество. Имайте предвид, че Google счита, че много сайтове са полезни като бази от знания, които надхвърлят Wikipedia и Wikidata. Той може да разгледа източници като IMDB и Yahoo Finance като полезна информация за фактите и същностите и да извлича информация от тях, според търсената фраза.