Какво е LSI (Latent Semantic Indexing) и как да го използваме в SEO?

Латентно семантичното индексиране оказва изключително влияние днес при оптимизирането на уеб сайтове . То “ преобразява “ съдържанието така , че да изглежда написано за потребители , а не просто търсещи машини . Само по себе си LSI представлява математически модел , който има за цел да установи и “ разбере “ връзките между ключови думи , понятия и концепции .
Когато търсещите машини обхождат страниците на уебсайт, те „разглеждат“ и събират най-използваните думи и фрази, за да идентифицират ключовите думи за конкретната страница.
При анализа на страницата чрез този метод стоп думите от типа на предлози и съюзи не се взимат под внимание. В допълнение – LSI търси думи, които се използват в един и същ контекст, защото се счита, че така те ще имат подобно значение или специфична връзка помежду си. Пример: ако търсите информация относно известна личност например Роджър Федерер, то ще откриете богата информация за тенис турнирите, в която дори не се споменава името му! Така търсачките, използвайки LSI, предоставят на потребителя релевантна информация на заявката за търсене, без непременно тази заявка да присъства в информацията.
Как работи LSI?
В повечето случаи най-често използваните думи в даден език не носят никаква семантична стойност. Именно поради това е и първата стъпка, която LSI изпълнява – да премахне тези думи, за да останат само думите с високо значение за съдържанието или определящи цялата концепция / смисъл / на съдържанието. Макар и да звучи просто и лесно, всъщност никак не е и начините за определяне на една дума като стойностна за дадено съдържание са много, но най-честите стъпки са следните:
- Премахване на съюзи от изречението
- Премахване на предлози
- Премахване на често използвани прилагателни
- Премахване на често използвани наречия
- Премахване на думи, които се появават във всеки документ в индекса
- Премахване на думи, които се появяват в един единствен документ
- Премахване на думи като „обаче“, „защото“, „понеже“ и други подобни.
- Премахване на местоимения
Но това, както споменахме и в предното изречение, са само част от методите. Истината е, че LSI в комплект с RankBrain технологията се „учи в движение“ и анализира всеки документ индивидуално и го сравнява с останалите документи в индекса, докато си създаде всеобща представа за това кой документ къде трябва да бъде класиран по релевантност за всяка една заявка, която потребителят търси!
Защо LSI?
Без латентно семантично индексиране SEO ще се сблъска с огромни предизвикателства и потребителите ще получат резултати при търсене, които нямат нищо общо с намерението им заложено зад заявката, която са въвели. Тези предизвикателства произтичат от ограниченията на булевото търсене, където има само „истински / фалшиви“ стойности. Това означава, че за да извлечете информация, можете да прецизирате търсенето си с команди AND, OR и NOT. По този начин комбинирате или изключвате термини от търсенето си.
Както всички знаем, човешкият език не е толкова прост. Две най-често срещани предизвикателства, когато Boolean се използва за търсене на текст, са синонимията (няколко думи, които имат сходни значения) и polysemy (думи, които имат повече от едно значение). Можем да си представим как използването на булевото търсене може да върне неподходящи резултати и / или да пропусне съответната информация.
LSI търси фрази, свързани с заглавието на вашата страница. След като дадена тема е определена на определена страница, тя има потенциала да класира съответните заявки за търсене (или както SEO да ги нарича, частични съвпадения на ключовите думи) не само за точните заявки за съвпадение на ключови думи, но и за свързаните с тях думи и фрази.
Съвет от Serpact™: Създавайте небрандово съдържание!!! Това ще Ви гарантира, че търсещите машини ще виждат връзката между вашата търговска марка и предлаганите от вас услуги / продукти (вашите не-брандирани ключови думи). След като завършите проучванията, за да определите темата и групата ключови думи, които искате да таргетирате, винаги имайте предвид потенциалните клиенти и посетителите на уебсайта си: създайте проницателни, ангажиращи и уникални публикации в блогове.
В крайна сметка продавате услуги и продукти на хора, а не търсачки!
Малко повече за технологията LSI
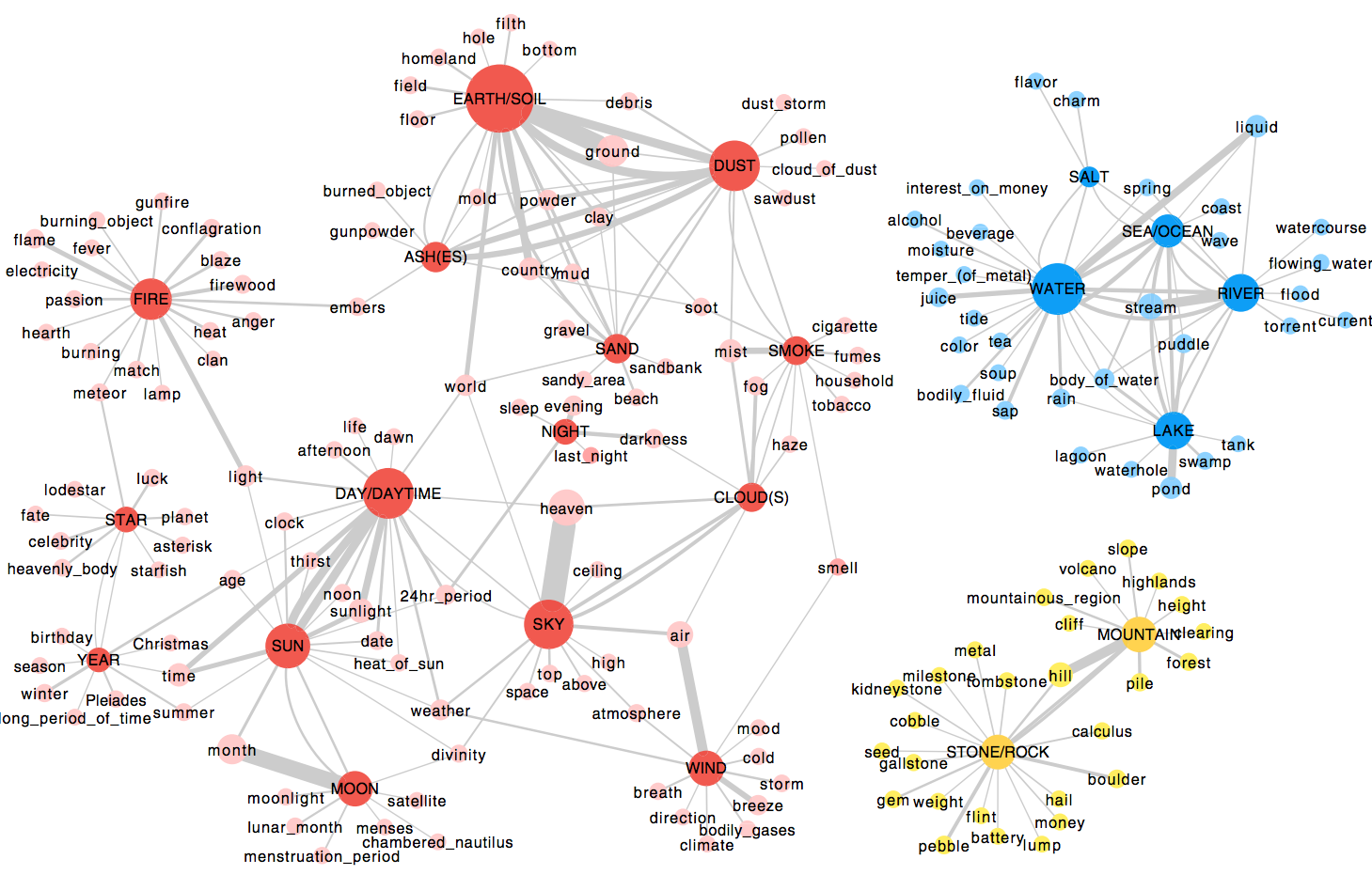
След като LSI филтрира думите със смислово значение за дадено съдържание, както и документите, следващата стъпка е да генерира матрица за термини. Това e понятие за много голяма мрежа, съдържаща документи по хоризонталната ос и съдържащи думи по вертикалната ос. За всяка съдържаща дума в списъка преглеждаме съответния ред и поставяме бройката пъти, в които думата се появява в колоната за всеки документ, в който се появява тази дума. Ако думата не се появи, поставяме нула.
Правейки това за всяка дума и документ в нашата колекция ни дава предимно празна мрежа с рядко разпръсване по хоризонталната ос. Тази мрежа показва всичко, което знаем за нашето събиране и анализ на документи. Можем да изброим всички съдържателни думи във всеки документ, като потърсим по хоризонталната ос в съответната колона или да намерим всички документи, съдържащи определена съдържателна дума, като разгледаме съответния ред.
Забележете, че нашето подреждане е двоично – квадрат в мрежата ни съдържа или цифра, или нула. Тази голяма мрежа е визуалният еквивалент на генеричното търсене на ключови думи, което търси точни съвпадения между документи и ключови думи.
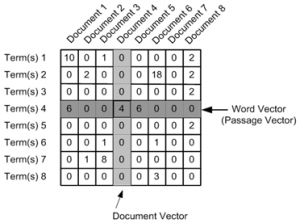
Ключовата стъпка в LSI разлага тази матрица с помощта на техника, наречена разграждане на единична стойност. Математиката на тази трансформация е извън обхвата на тази статия, но можем да получим интуитивно разбиране за това, което прави SVD (Singular Value Composition), като мислим пространствено за процеса.
Разграждане до единична стойност – Singular Value Composition
Представете си, че държите тропически риби и се гордеете с аквариума си дотолкова, че искате да представите снимка на списание. За да получите най-добрата възможна картина, вие ще искате да изберете добър ъгъл, от който да направите снимката. Искате да сте сигурни, че възможно най-много от рибата е видима във вашата картина, без да е скрита от други риби на преден план. Също така няма да искате рибите да се сдърпват заедно, но по-скоро да бъдат заснети от ъгъл, който показва, че са добре разпределени във водата. Тъй като вашият аквариум е прозрачен от всички страни, можете да вземете различни изображения от горе, отдолу и от целия аквариум и да изберете най-добрият.
В математически смисъл Вие търсите оптимално картографиране на точки в триизмерно-пространство (рибата) в равнина (филмът във вашия фотоапарат). „Оптимално“ може да означава много неща – в този случай това означава „естетически приятен“. Но сега си представете, че целта ви е да съхраните относителното разстояние между рибите колкото е възможно повече, така че рибата от противоположните страни на аквариума да не се наслагва в снимката. Тук ще правите точно това, което алгоритъмът SVD се опитва да направи с много по-голямо пространство.
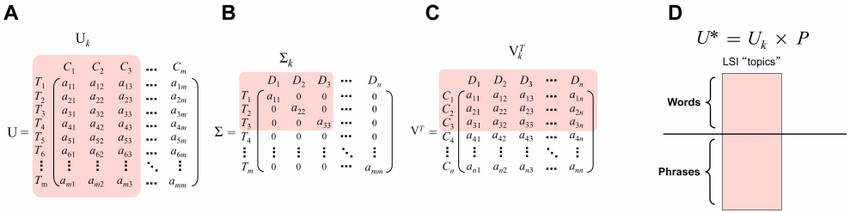
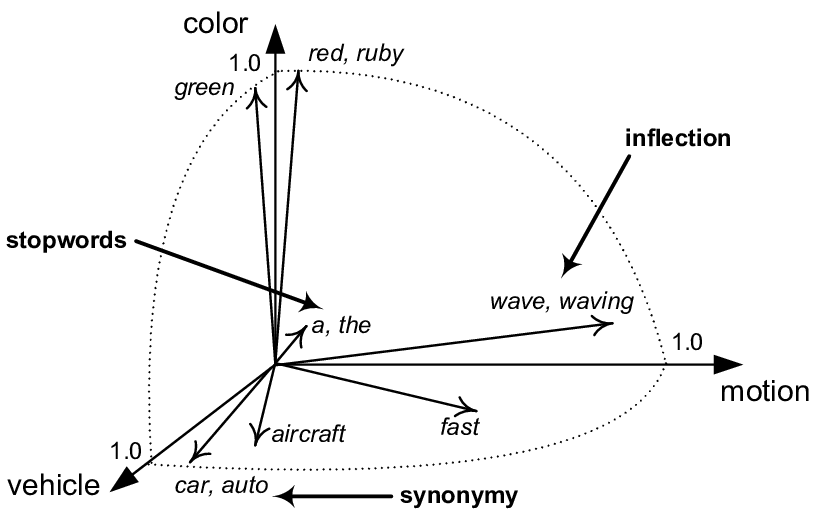
Вместо да картографираме 3-измерно-пространство в 2-измерно-пространство, обаче, SVD алгоритъмът отива в много по-големи крайности. Типично пространство за термините може да има десетки хиляди размери, както и да бъде проектирано на по-малко от 150. Въпреки това принципът е същият. Алгоритъмът на SVD запазва възможно най-много информация за относителните разстояния между векторите на документи, като ги свива надолу в много по-малък набор от размери. При този колапс информацията се губи и съдържателните думи се наслагват един върху друг.
Информационната загуба звучи като лошо нещо, но тук е позитивно. Това, което губим, е шумът от нашата оригинална матрица за терминологичен документ, разкривайки прилики, които бяха скрити в събирането на документи. Подобни неща стават по-сходни, докато несъответните неща остават различни. Това редуктивно картографиране е това, което дава на LSI неговото привидно интелигентно поведение, че може да свързва семантично свързани термини. Наистина използваме собственост на естествения език, а именно, че думите с подобно значение имат тенденция да се срещат заедно.
5 начина да намерите LSI ключови думи
След като вече сте експерт по LSI и защо е важно, нека да преминете през различните начини, по които можете да намерите допълнителни ключови думи, които ще искат да се включат в бъдещите съдържание и публикации в блога.
1) Обикновено Google Търсене
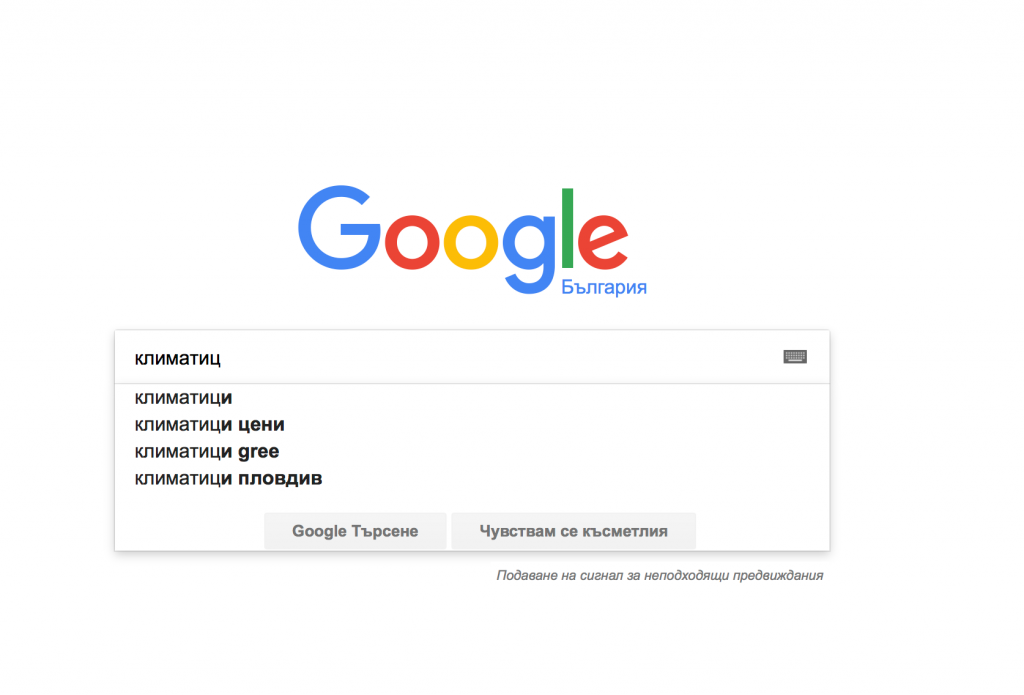
Един от най-лесните начини за намиране на LSI ключови думи е самият Google. Когато въведете дума в полето за заявка за търсене, той автоматично показва ключовите думи, свързани с конкретната заявка.
Да използваме като пример думата „климатици“. Първоначалното търсене на думата осигурява тези резултати показани на изображениято в лявата страна.
Използване на списъка с ключови думи като отправна точка за потенциални ключови думи LSI е добро решение, защото разкрива какво Google вече свързва с вашите основни ключови думи.
Най-добрата част? Този метод е 100% безплатен!
2) Използвайте инструмента за планиране на ключови думи чрез Google AdWords
Ако имате достъп до Google AdWords, можете също да използвате инструмента си за планиране на ключови думи.
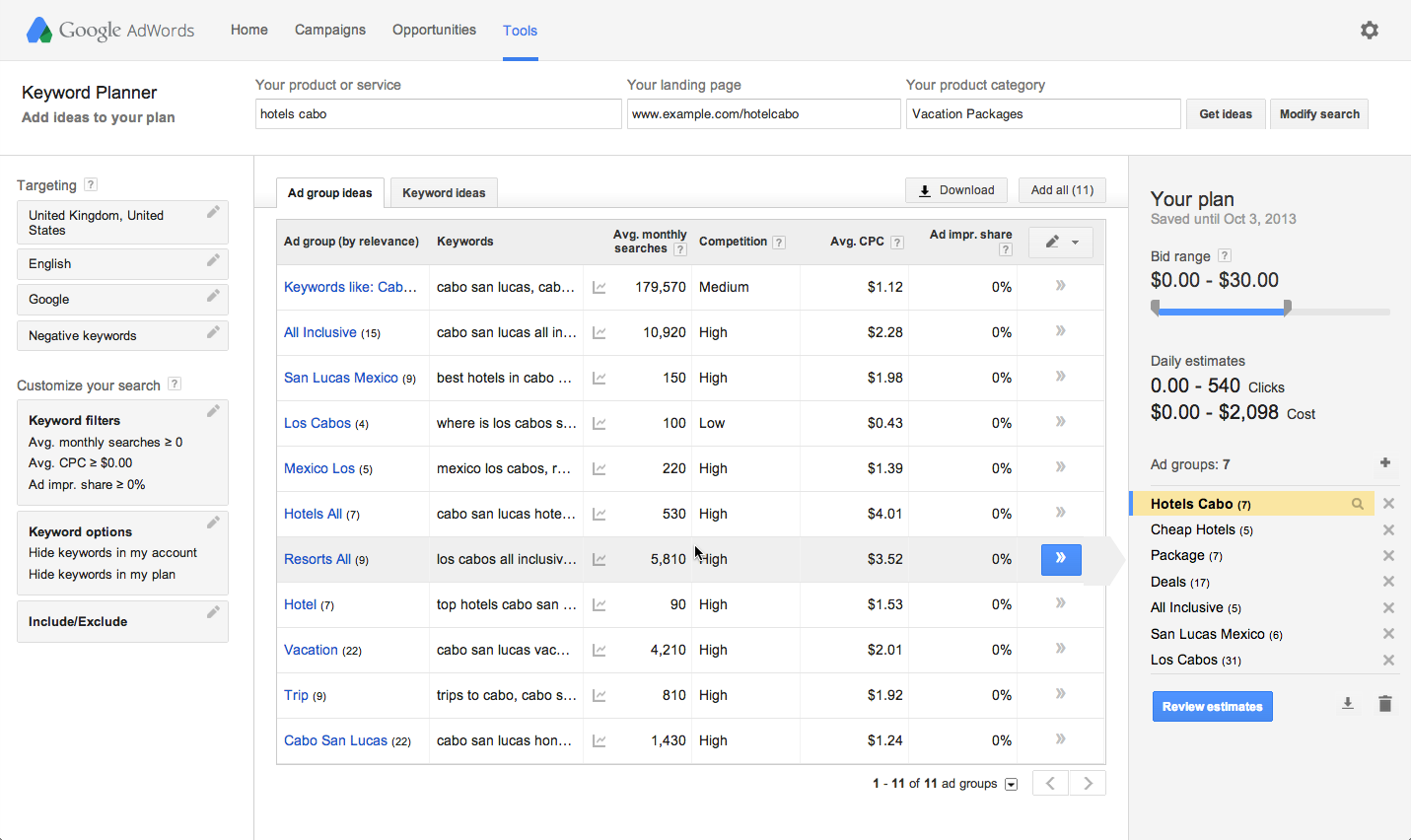
Този инструмент е спряган като един от най-лошите за анализ на ключови думи в SEO и това до голяма степен оправдано е така. Причината е, че практиката на нас специалистите ни е показала, че той прикрива доста думи, които са ценни за бизнеса. В същия момент дава преднина на други думи, които нямат кой знае каква стойност, но пък инструмента подава висок обем на месечно търсене и добра цена на клик.
Откриването на LSI ключови думи с него е сравнително трудно и изисква доста време, а и опит за да се филтрират думите качествено. В случай, че имате добри познания върху Excel, както и добре познавате нишата си, бихте могли да използвате този инструмент като отправна точка, но не разчитайте само и единствено на него.
Започнете, като добавите термина в първоначалното поле на заявката. Кликнете върху „Получаване на идеи“ и ще бъдете пренасочени към страница, която предлага подходящи ключови думи и представа за това колко конкурентен търсене ранглиста са за срок каза.
3) Възползвайте се от инструмента за създаване на база от данни за ключови думи в SERP.com
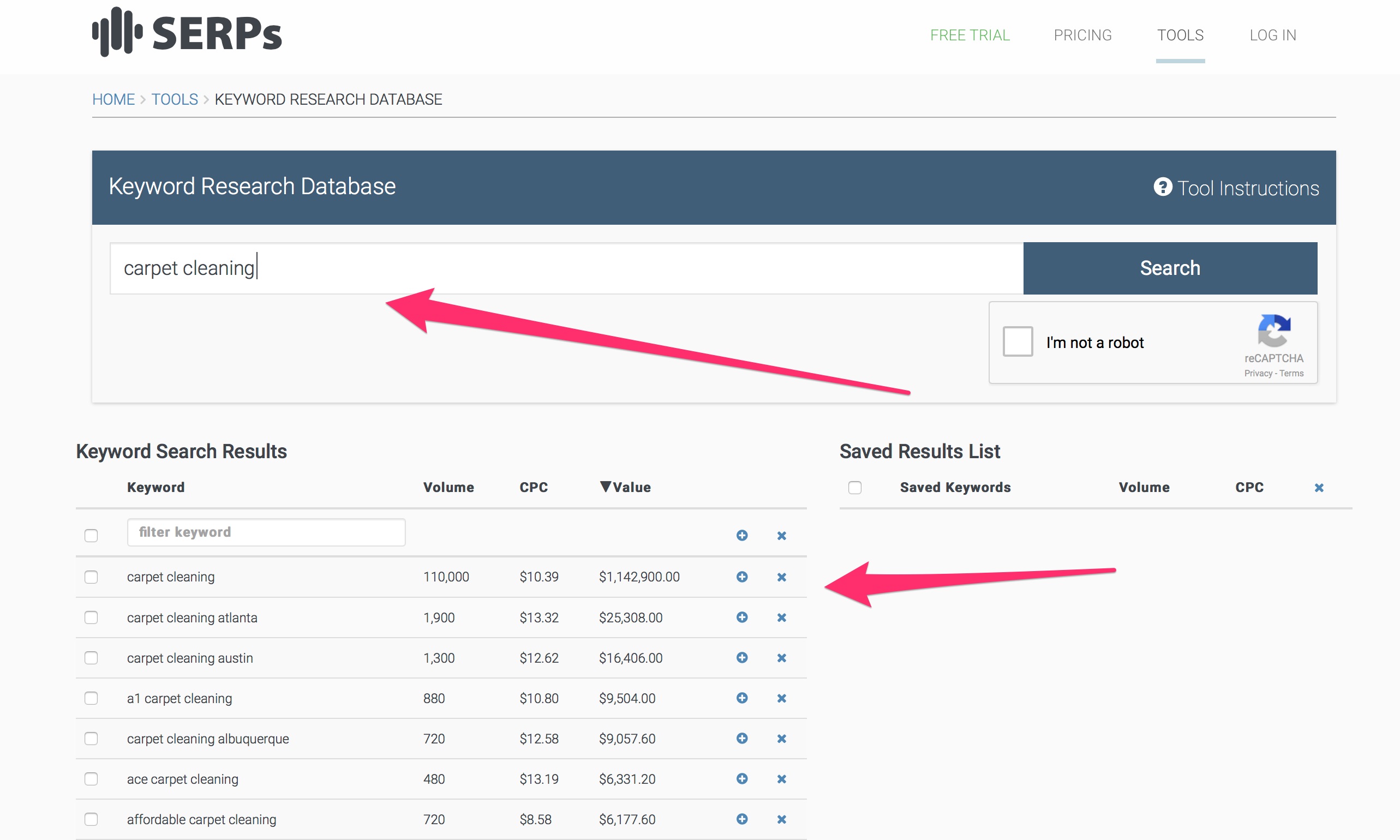
Друг безплатен инструмент, който можете да използвате, идва от SERP. Инструментът за бази данни за изследване на ключови думи е много подобен на инструмента за планиране на ключови думи на Google. Просто добавете заявката си в лентата за търсене и ще получите резултати въз основа на обема на търсенията и CPC.
4) Използвайте генератора на ключови думи за LSI
Генераторът на думи LSI Graph / LSI е друг безплатен инструмент, специално създаден за идентифициране на LSI ключови думи. И както
вероятно може да предположите, това просто изисква от потребителите да добавят термин в лентата за търсене, за да генерират списък със свързани ключови думи.
Практиката ни показва, обаче, че от инструмента има все още да се желае много, затова използвайте го внимателно. Доста често в него ще откривате думи, които нямат много общо с публикацията, която изготвяте или страницата, за която пишете съдържание. Понякога подадените думи нямат и голяма стойност и логика да бъдат част от съответната бизнес ниша, но инструментът е обект на постоянни подобрения, така че резултатите, които ще връща занапред ще бъдат все по-добри.
5) Опитайте Ubersuggest
И накрая, друга безплатна програма, която можете да използвате, за да идентифицирате потенциални LSI ключови думи, е Ubersuggest. Трябва само да въведете основната си ключова дума и инструментът ще изготви списък със сродни заявки за търсене въз основа на обем, трудност и CPC.
Може да се наложи да използвате допълнителни разширения за браузъра си, за да добиете представа за търсенето и бидовете на думите. Ubersuggest е един от най-старите инструменти за анализ на ключови думи. Използва се, както от професионалисти, така и от маркетолози и дори начинаещи в оптимизацията за търсачки. Инструментът генерира доста често идеи, за които просто няма как да се досетите, затова бихме могли да го определим и като инструмент за брейнсторминг на ключови думи.
Изберете думи, които да добавят контекст, но не прекалявайте
LSI ключовите думи трябва да са много подходящи за вашето съдържание. В случая, ако решим да пишем публикация посветена на филма „The Aviator“ със заглавие „10 неща, които не знаехте за авиатора“, то тя трябва да включва само LSI ключови думи, които се отнасят до филма. При въвеждане на заглавието на филма се появява и фразата „Авиаторен колеж“, но тя няма нищо общо с филма и на свой ред не добавя стойност към вашето съдържание.
Нещо друго, което ще искате да избегнете, е да не надхвърляте съдържанието си с избраните от вас ключови думи за LSI. Чудесен начин да прецените това е чрез препрочитане на съдържанието си след добавяне на ключовите думи. Ако дадена дума не звучи естествено, премахнете я.
Не забравяйте, че LSI не е всичко в SEO
Въпреки че има доста сложно име, не е необходимо да сте гуру на LSI технологията и разработването на уебсайтове, за да разберете латентно семантично индексиране. Имайте предвид обаче, че това е само един фактор, който определя колко добре се класира съдържанието ви в търсачките. Ефективната стратегия за SEO оптимизация също трябва да включва подходящи входящи линкове към Вашия сайт, подходящи алт тагове, добра техническа оптимизация и куп други неща.
Струва си обаче времето, което ще отделите, за да проучите LSI ключовите думи, релевантни на съдържанието, което създавате, защото така се превръщате в абсолютен фен на Гугъл, а той съответно ще Ви възнагради щедро.