Обзор на уебинар: Make your website easier to be crawled by Googlebot with Murat Yatagan

Serpact: Здравей, Мурат! За нас е чест да си наш гост днес. Моля, разкажи за теб, как навлезе в тази област, как стигна до Гугъл и т.н.?
Мурат: Бях в университета и правех проучване, правейки моята магистратура, като research assistant и работа по невронни мрежи. Винаги съм искал да продължа с докторантура по тази материя. И тогава, по програма за академичен обмен, аз отидох за 2 седмици в Дъблин, Ирландия. И аз осъзнах, че има няколко компании там, защо да не кандидаствам в някоя от тях. И Гугъл беше най-добрата възможна оферта. И така аз започнах работа в Web Spam екипа, също така познат и като Search Quality /в наши дни той се казва вече Trust and Safety/, също като product top analyst, и се опитвах да открия Web Spam проблеми, в Гугъл индекса, в различните езици. След 5 години аз реших да предприема предизвикателство за мен самия, да започна мой собствен бизнес, върнах се в Турция. Там събрах екип и започнах да консултирам различни клиенти в областта на SEO, клиенти от САЩ, Великобритания, Германия, Полша, Турция, Австралия. Някои бяха доста големи фирми, но не мога да ги спомена, защото имаме NDA, а други бяха малки стартиращи бизнеси. След това реших да се върна в Европа и от 6 месеца вече работя в Brainly. В Brainly имаме вече 150 млн уникални потребителя месечно, управляваме над 10 домейна и обслужваме 25 различни езика.
Serpact: Кое беше голямото предизвикателство за теб, когато работеше в Гугъл? Всекидневната ти работа, или нещо по-специално в твоята кариера там?
Мурат: Най голямото предизвикателство, и в същото време много удовлетворяващо беще това, чеработех с много увни хора, много големи умчове и в същото време хора, които работят здраво. Конкуренцията в екипа беше много голяма, но и всеки вършеше най-доброто, на което е способен. Уникална атмосфера, където ти се учиш всеки ден. Работата ми там никога не е била рутинна и досадна, а вдъхновяваща и предизвикателна, пълна с уникални идеи всеки ден.
Serpact: Значи работата в Гугъл е креативна и те стимулира да раждаш нови идеи и да се развиваш?
Мурат: Напълно. Например, моят мениджър ми каза, че мога да използвам 20% от времето си, за да реша аз по какво да работя. Аз реших да работя с различни екипи по различни проекти. 20% не е малко, това означава, че всяка седмица по 1 ден ти работиш нещо различно. Има и нещо много интересно при наемане на хора в Гугъл – какво биха правили те, ако имат дадено свободно време – дали ще гледат YouTube видео-та или ще мислят по проблем, който чака разрешаване.
Serpact: Това е страхотно, че Гугъл дават свобода за развитие и стимулират идеите, родени от хората в екипа.
Мурат: Да, така е. Но това не значи, че когато ти дойдеш с една идея, и те ти казват – давай, правим го. Пръво ти трябва да представиш данни, да защитиш идеята си и нейният смисъл и полезност, и тогава, тя се прилага в начален етап, lightweight. Когато идеята напредне, и се види че тя носи резултати, вече се работи по-надълбоко с нея, и се назначава специален екип за това.
Serpact: Нашата тема днес е Crawl budget, ти ни каза, че си подготвил презентация, така че я очакваме с нетърпение, да ни покажеш твоите знания, и някоя тайна, може би. А вие, ако имате въпроси, задавайте ги, за да ги зададем ние на Мурат.
Мурат: Нека споделя екрана си, и ще започна да показвам. Днес ще говорим как да направите страницата си да бъде лесно обходена от search engines bots, и в частност Google bot, за който знам най-много.
Ето и съдържанието ни за днес:
- Животът на един URL
- Какво е crawl budget
- Значими фактори, влияещи на обхождането
- Изграждане на домейни, лесни за обхождане
Животът на един URL
Животът на един URL адрес означава пътят, който той има, от публикуването му в интернет, и как след това търсещите машини взаимодействат с него.
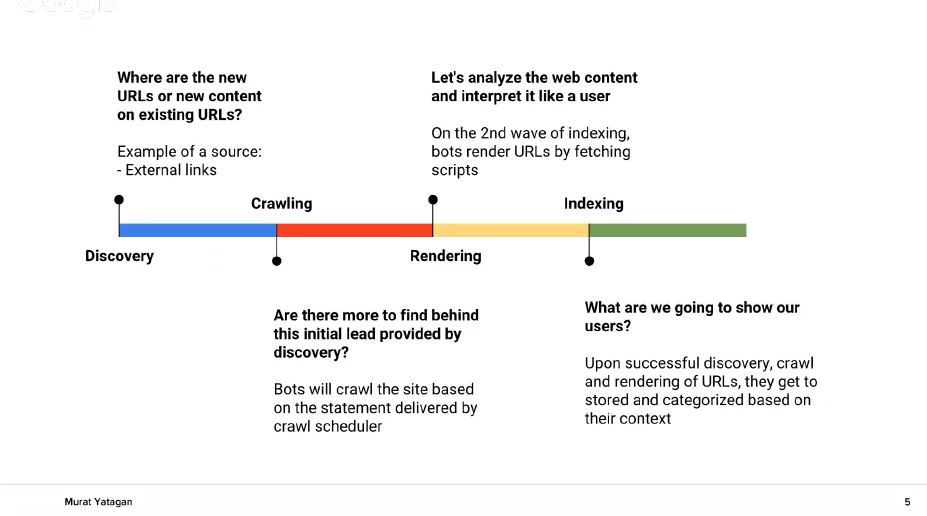
А. Първата стъпка е адресът да бъде открит /Discovery/. Знаете, че една от функциите на Гугъл е да организира уеб-пространството. Така, чрез обхождане на старите, вече познати адреси на Гугъл, търсачката може да открие нови адреси. Но според различна мета-информация и параметри, като старият PageRank например, Гугъл преценява кои адреси да обходи първи. Гугъл също преценява по колко адреса на ден да бъдат обходени за даденият сайт.
Б. По този начин процесът преминава към фазата обхождане /crawling/. Обхождането се извършва от Гугъл бот. Ботът преценява има ли още адреси зад този, открит сега адрес. Ботът също преценява и честотата на обхождане. На този етап Гугъл бот анализира HTML sitemaps и вътрешните линкове, за да открие нови адреси.
В. Третият етап в процеса е рендерирането /rendering/. Тогава Гугъл изпълнява скриптовете в страницата и я „разглежда“, като потребител. Целта на това е за да разбере контекста на страницата.
Г. Четвъртата и последна фаза е индексирането /indexing/ – тоест – записването и категоризирането на страницата, според нейното съдържание и контекст. Гугъл запазва тонове информация за всяка страница, за да може да я определи и категоризира. След това този адрес се подава към ranking алгоритъма, за да може да се класира адреса според неговите параметри. Именно при ранкинг алгоритъма се случва магията.
Serpact: Бърз въпрос за Discovery фазата. В интернет много се спекулира, че откриването на нови адреси става вече чрез machine learning алгоритъм. Вярно ли е това?
Мурат: Да, machine learning алгоритъмът е дефакто техника, която сама се обучава. И тя може да се използва в много процеси. Така че това е възможно.
Концепцията зад Crawling
Имаме информация кои адреси могат и кои не могат да бъдат обхождани. Гугълбот със сигурност уважава и следва указанията на robots.txt файла. Така че ако искате даден адрес да не бъде обходен, вие трябва да не го включвате в sitemap и освен това да ограничите достъпа на ботовете до него – с някаква парола, или друго ограничение. Гугъл бот обикаля публично-наличните URL адреси, от страница на страница, от линк на линк, и така обхожда съдържанието. И след това я изпраща в Google data centers.

Гугъл трябва да планира колко адреса да обходи на ден, и колко често да посещава сайта, защото дефакто трафикът се заплаща и хостинга се товари.
Какво е Crawl Budget
Един от факторите, който определя crawl budget е авторитета на страницата. Обхождането тръгва от страницата с най-висок PageRank. Ние не знаем PageRank колко е, той е много комплексен алгоритъм, но можем приблизително да го определим, като знаем коя страница е по-важна, прегледаме лог файловете си, също като знаем, че началната страница се обхожда доста по-често от другите страници. Това е нормално, защото всички други страници имат линкове към началната страница. И обикновено потребителите посещават началната страница най-много. Дори и да попаднат /чрез търсеща машина/ на някоя вътрешна старница, те почти винаги посещават и началната страница. Освен това обхождането не върви на случаен принцип. Обикновено то започва да обхожда първо новото съдържание /fresh content/.
Дефиниции и параметри

Всяко посещение от бот на една страница има стойност и то натоварва сървъра на домейна, който посещава, затова се въвеждат ограничения в посещенията /quota/. Също така crawl schedulers преценяват колко URLs от даден домейн ще бъдат обходени за даден период от време, и този план в SEO индустрията се нарича crawl budget. Той не е статичен и може да бъде променян. Ако вашият сървър /хостинг/ реагира бързо, тогава Гугълбот може да обходи 1000 URLs за 10 минути. Ботът си задава рамка, например: Аз ще обходя 1000 URLs от този сайт, но за това няма да отделя повече от един час. И ако страниците ви не се зареждзат бързо, ботът няма да може да обходи тези 1000 адреса и ще се откаже някъде, достигайки своят времеви лимит. Именно тук говорим за crawl optimization – вие трябва да се подсигурите, че новото ви съдържание и най-важните ви страници са бързи и лесни за обхождане от Гугъл бот.
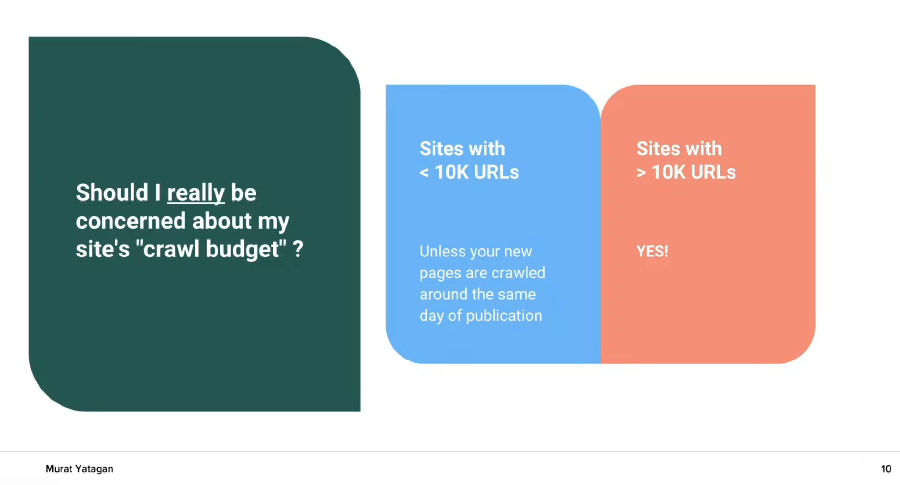
Трябва ли да се притеснявате за вашият crawl budget? Ако сайтът ви има по-малко от 10 000 URLs – обикновено не. Ако са повече от 10 000 URLs – Да! Ако сайтът ви има 1 милион URLs или повече, crawl budget трябва да ви е топ-приоритет.
Значими фактори, влияещи на обхождането
Нека се фокусираме на тези 5 фактора, защото те са най-важни и най-добре обхващат процеса на обхождане /crawling/.

1. Capacity to respond quickly
Ако вашият хостинг отговаря бързо на заявките на Гугъл бот, то вероятността честотата на тези заявки /crawl rate/ да може да се повиши е много възможна. Също така и едно посещение от ГугълБот да преминава по бързо. В тази част можете да подобрите Time to last byte /TTLB/ и средното време, за което ботът изтегля една URL страница.
2. Domain health
Ако вашият сайт има доста грешки от типа 50x, 40x, soft 404 и те се увеличават – бъдете внимателни. Ако имате също така много redirect chains, повредени редиректи, неправилна употреба на robots.txt и sitemap.xml – това са фактори, които влияят лошо на „здравето“ на вашият домейн и на обхождането на сайта ви от ботовете на търсещите машини.
3. Quality of pages
Ако намалите страниците с малко или липсващо съдържание, или дублираните страници – това ще ви донесе ползи – по-добро обхождане на сайта ви от ботовете. Старайте се да поддържате високо ниво на съдържанието във вашият сайт. Защото, когато Гугълбот обходи сайта ви, и открие много страници с липсващо или нискокачестевно съдържание, той си казва: „Този сайт е от предимно страници с нискокачествено съдържание, защо да го обхождам толкова често?!“. И тогава той намаля честотота на обхождане за този сайт.
Serpact: Мурат, бърз въпрос – при доста от онлайн магазините става дублирано съдъргание, при продукти, категории и т.н. Има начин това да се коригира, разбира се, но това проблем ли е?
Мурат: Да, нормално е да има дублирано съдържание в магазините. Трябва да поработите за неговото коригиране – с canonical таг, или преправяне на архитектурата на сайта. Също, ако имате вътрешно търсене в сайта, или филтър по 50 различни параметъра, който генерира дублирани страници – изключете ги от индексирането. Те не са нужни на Гугъл.
Никола: Дали ти препоръчваш да се комбинират различни варианти на продукта, като например цвят или размер, в един продукт, а не да се правят много различни продукти с тези варианти?
Мурат: Трябва да анализирате и да проверите какъв е обемът търсене за тези продукти. Ако имате голям обем търсене, например, за Nike Blue /20 000 търсения/ или Nike Red /5 000 търсения/ – то тогава направете страници за тях, защото има смисъл. Помислете и как ще се почувства клиентът, когато попадне на тези страници.
4. Internal linking structure
Това е много важна точка. Тук трябва да помислите за вашата структура и страници – на какво разстояние се намират те, на колко клика могат да бъдат достъпени. Ако те са толкова надълбоко и се откриват трудно, това е лошо – те няма да бъдат достигнати от потребителя, нито ще бъдат обходени от Гугълбот, а и няма да получат Pagerank стойност. Тогава помислете за преправяне на вашата структура на сайта, или използването на тагове, или други методи, които да изведат напред това съдържание.
5. Freshness
Относно новото съдържание – погрижете се то да е видимо, да се достига и обхожда бързо и лесно от Гугъл, защото потребителите търсят ново съдържание и Гугъл също предпочита него. Новото съдържание подсилва бранда, защото когато аз имам нова информация по дадена тема, аз съм по-добре информиран и правя по-добри заключения, по-актуални. Освен това PageRank отслабва във времето и ние трябва да го „поддържаме“ с ново /свежо/ съдържание.
Никола: Мурат, един въпрос от нашата аудитория, защо TTLB /Time to last byte/, а не TTFB /Time to first byte/, и какво ще ни кажеш за FCL /First Content Load/?
Мурат: TTFB е важен и той показва кога Гугъл започва да зарежда страницата. FCL и TTFB са еквивалентни. Но за да определи Гугъл Page Score на страницата, той трябва да я обходи, да мине през нея цялата /изплозвайки техника като Lighthouse/, и тогава на края да изведе TTLB. TTLB е най-важен.
Capacity to respond quickly – page speed optimization
Това е случай на клиент, който дойде за помощ. Той имаше ниска честота на обхождане, когато дойде при нас, и скоростта на изтегляне на страниците му беше ниска – около 1000 милисекунди.
Ние подобрихме скороста му /page speed оптимизация и подобряване на вътрешните линкове/ и активирахме по-бързо обхождане от Гугълбот. След това обхождането на страници в сайта на клиента скочи няколко пъти, както виждате на графиката. Малки стъпки, но с голям ефект.
Същото се отнася и до load time. Колкото по-добра скорост постигате, толкова по-добре и често Гугълбот ще обхожда сайта ви. Но това повлиява положително и ранкинга ви в SERP.
Domain health – site sanity exploration
Долната графика показва зависимоста: увеличаването на 4xx и 5xx грешки води до намаляване честотата на обхождане на сайта от Гугълбот. И коригирането на тези грешки възвръща предишните добри метрики.
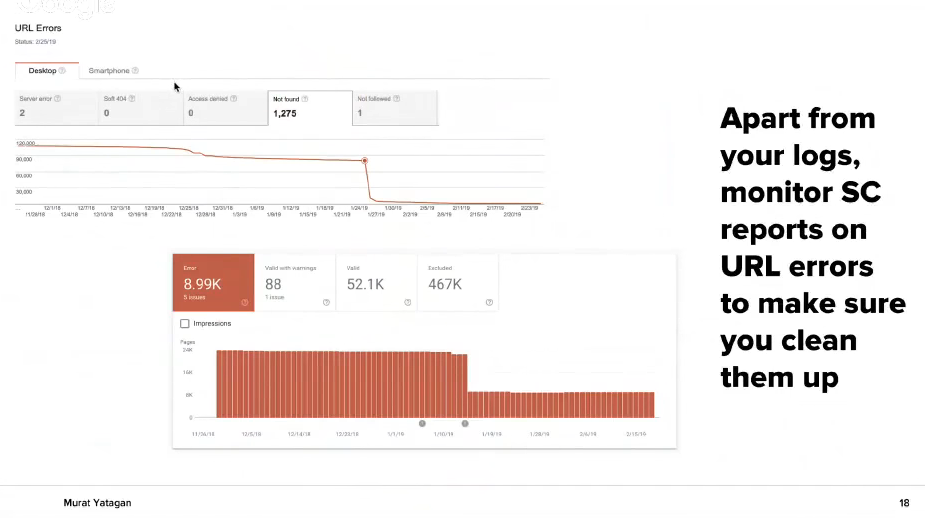
Също така, следете редовно URL грешките в Google Search Console. Ако имате проблеми там, работете по тяхното отстраняване, както е показано на картинката, за да ги намалите или отстраните максимално.
Quality of pages – Quantify the quality
Качеството също е нещо, което може да се измери. На следващата графика показвам връзката, която имат страниците, позиционирани в топ 1-3 с техният load time и с техният среден брой думи.
Има пряка връзка между уникалното и богато съдържание и ранкинга, също така между честотата на обхождане и ранкинга. Отстранете дублираното съдържание в сайта ви. Това ще доведе до това важните страници в сайта ви да бъдат обхождани по-често.
Internal linking structure – PageRank propagation
Тази графика показва честотата на обхождане според дълбочината на URL адреса в сайта. Страниците, които са дълбоко в сайт-структурата и са далече от началната страница ще бъдат обхождани по-малко. Затова трябва да промените архитектурата на сайта според нуждите на потребителя. Когато имаме сайт с дълбока структура, категории и подкатегории, е по-трудно те да бъдат показани добре на бота. Затова има различни методи, като тагове, pagination, HTML sitemaps и други, за да подадете всичко на Гугълбот за обхождане.
Freshness
PageRank отслабва във времето, ако няма ново съдържание или активност. Също така Гугъл продължава да търси нови страници или добавено ново съдържание към съществуващи вече стари страници. Затова поддържайте сайта си актуален и свеж и публикувайте в него често.
Съвети:
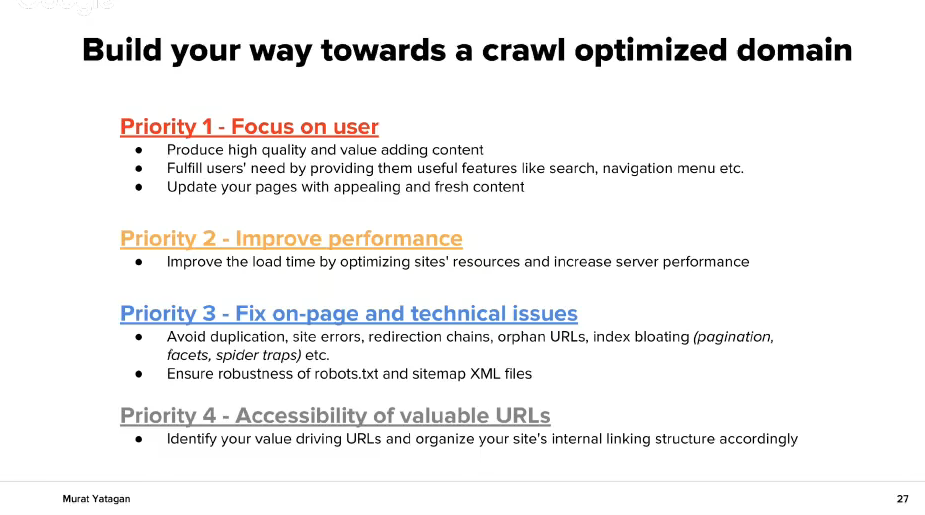
Приоритет N 1 – Фокусирайте се на потребителя:
- ново качествено съдържание, даващо стойност
- удовлетворете нуждите на потребителя
- обновявайте вашите страници с ново съдържание
Приоритет N 2 – Подобрете представянето:
- Подобрете load time с корекции в ресурсите на сайта и представянето на сървъра
Приоритет N 3 – Поправете он-пейдж и техническите проблеми:
- Избягайте от дублираното съдържание, redirection chains, orphan URLs и т.н.
- Тествайте robots.txt и sitemap.xml дали работят правилно
Приоритет N 4 – Достъпност на стойностните URL адреси
- Преценете вашите най-важни URL адреси и организирайте структурата на сайта си така, че тя да се върти около тях
Благодаря ви!!!
От аудиторията: Какво можем да направим с 10 милиона URLs в нашият сайтмап и как да ги приоритизираме – според keyword volume или по друг параметър?
Мурат: Вие би трябвало да подредите адресите по възраст, по дата на публикуване. Например – карта от януари, карта от февруари, и т.н. Така можете да стигнете до 50 сайтмап-а, например. Така ще постигнете indexing ratio на всеки пакет от адреси. Но също така трябва и правилно да категоризирате сайта си /по контекст и по важност/, и от там самите карти на сайта.
Никола: Какво мислиш за бъдещето на SEO? Да очакваме ли някакви изненадващи промени или не?
Мурат: Сега освен 10 резултата, Гугъл показват все повече и featured snippets. Вече навлизат и Alexa Echo, Google Home и други и те променят правилата. Много хора използват информационни търсения, някои транзакционни, и първото нещо е да се разбере намерението на определеното търсене.
Смятам че скоро когато потърсите нещо, ще се случва следното: Ако потърсите за рецепти – ше получите featured snippets. Ако потърсите текстове на песни, ще получите featured snippets, ако потърсите билети за самолет – ше получите featured snippets, където можете да резервирате. Това променя SERP-а. Гугъл ще разбира по-добре какво искате вие и ще ви го дава.
PDF: How to create crawl optimized domains. – Copyrights (c) https://muratyatagan.com .





