Обзор на Google – Януари 2019

Тестовите сайтове може да нямат добра видимост органичните резултати както официалните сайтове
Не бива да се приема, че тестовите сайтове ще имат същите резултати на видимост в търсенето както регулярните сайтове, защото Гугъл може да ги третира различно. Гугъл би мобъл да прецени да не рендерира дадени страници на тестове сайт напълно, защото няма смисъл да изхабява ресурси за това.
Гугъл решава дали даден Title tag да се използва за класиране или не
Промените в заглавията на заглавията са сложни за обработката на Google, тъй като търсачката трябва да прецени дали да се използва заглавния таг, предвиден за класиране и в резултатите от търсенето.

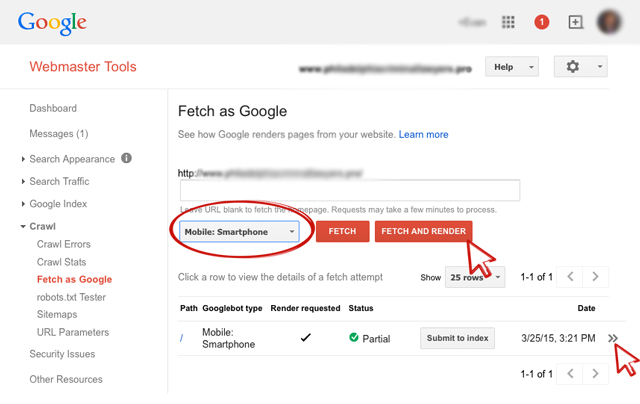
Няма да бъдете наказани, ако използвате FETCH & RENDER, но има лимити
Няма да бъдете наказани за това, че използвате този инструмент от конзолата на Гугъл, но може да бъдете рестриктирани в честотата му на използване.
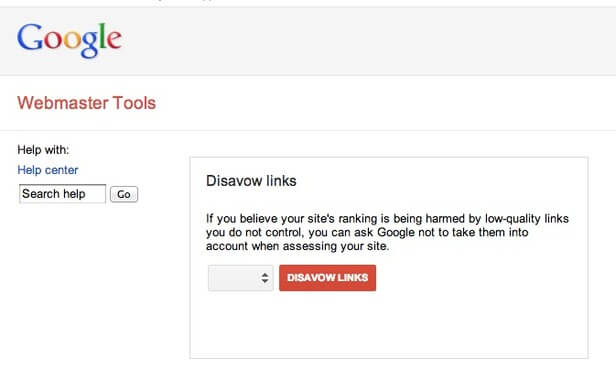
Използвайте DISAVOW ако имате съмнение, че ще получите ръчно предупреждение от Webspam екипа на Гугъл
Джон препоръчва да използвате инструмента Disavow, ако смятате, че екипът на WebSpam вероятно ще ви даде ръчно предупреждение за създадени връзки. Въпреки това, за повечето уебсайтове, които не се опитват активно да манипулират класирането с подозрителни практики за изграждане на връзки, не си струва да използвате инструмента за отказ.
Свежестта на съдържанието не се използва винаги като сигнал за класиране
Свежестта на съдържанието не винаги се използва като сигнал за класиране, тъй като не винаги има нужда страниците да се актуализират редовно, ако са актуални. Например академичните изследвания като цяло не се променят, въпреки че ако са написани преди много години.
Следвайте насоките за качество, но се фокусирайте върху UX
Джон препоръчва да се използват указанията за качество на уеб администраторите като ръководство за качеството на съдържанието (Search Quality Raters Guidelines), но предлага да не се фокусирате твърде много върху това, което Google прави от гледна точка на алгоритмите. Вместо това се съсредоточете върху създаването и оптимизирането на сайтове, които осигуряват добър потребителски опит.
GOOGLE изчаква определено време преди TIMING OUT повреме на рендеринг процеса
Googlebot изчаква определено време, за да бъде рендерирано съдържанието преди timing out, но това не може да се дефинира с определена продължителност. Препочъва се сервирането на съдържание да се случва възможно най-бързо – на сървърно ниво, чрез кеширане или динамичен рендеринг.
![]()
Organization Schema.org Type маркирането трябва да е имплементирано само на една страница
Маркировката на Schema от типа Организация трябва да е само на една страница, например на началната страница или на страницата за контакт, но се уверете, че не съществува на всички страници.
Lighthouse инструментът използва среден клас смартфон на 3G връзка
Анализът на Лайтхаус използва среден смартфон на 3G връзка за измерване на скоростта. Това може да обясни несъответствията между Лайтхаус и независими тестове, които биха могли да се извършват в много по-бърза Wi-Fi връзка.

GOOGLE ще премахне някои функции от старата версия на конзолата за уебмастъри
Google ще продължи да мигрира функции от старата версия на конзолата за търсене в новата версия, но някои функции няма да бъдат мигрирани и ще бъдат отхвърлени, например секцията Грешки при обхождане.
Създавайте страници, които се рендерират на сървърно ниво, така че ако Javascript се счупи, съдържанието да не бъде изтрито
Със страниците от рендерирани на сървърно ниво , които имат допълнителен JavaScript, се уверете, че те са създадени, така че ако JavaScript прекъсне, той не премахва съдържанието.
GOOGLEBOT може да не успее да обходи рендерирани страници на ниво сървър, където само съдържанието е рендерирано
Google може да обхожда страниците на сървърно ниво, ако в статичния HTML е налице цялата функционалност. Въпреки това, ако се визуализира само съдържанието, а връзките и структурираните данни не, то тогава, Google също няма да може да ги обходи.
GOOGLE подобрява предупрежденията си GSC на основата на стабилна версия на сайта
Google работи за подобряване на конзолата за търсене, така че предупрежденията да се задействат въз основа на стабилната версия на уебсайта. John е виждал случаи, в които Google временно не може да извлича ресурси, които задействат предупреждение в конзолата за търсене.
GOOGLE третира CDN сайтове по същия начин като не-CDN хостнатите сайтове
Сайтове, хоствани с помощта на CDN, не се третират по различен начин от сайтове, които не са с CDN, тъй като Google го вижда като друг начин за хостване на сайт.
GOOGLE третира XML сайтмаповете различно от HTML страниците
Google третира XML Sitemaps по различен начин от HTML страниците, тъй като те са машинно четими и не са предназначени за индексиране от търсачките.
За GOOGLE няма значение как са разделени и разпределени сайтмаповете
Google комбинира отделни Sitemap заедно, за да могат да бъдат обработени. Това означава, че уебмастърите трябва да решат как да разделят Sitemap.
Страниците, които блокират достъпа до тях от САЩ е необходимо да блокират и GOOGLEBOT за да избегнат Cloaking.
Ако трябва да блокирате достъп до съдържание в САЩ или Калифорния, ще трябва да блокирате и Googlebot, в противен случай Google ще види това като прикриване (Cloaking). Една от възможностите може да бъде да предоставите обща информация, която може да бъде видяна от посетителите в САЩ.
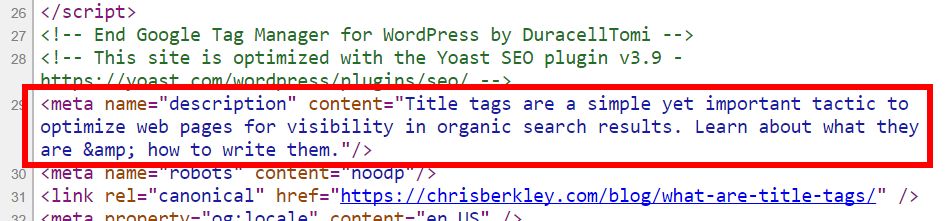
GOOGLE може да филтрира части от мета описание, ако счита, че те са филтриращи или спам.
Google може да филтрира части от мета описания, ако те се считат за спам или подвеждащи.





