Обзор на Google – Януари 2023

Дойде и време да споделим първия обзор на Google за новата 2023-та година. Нека да видим как започна януари месец и какво е новото от търсачката.
Google: Номерата на страниците в заглавията във вашия сайт не помагат за SEO
Alan Kent от Google сподели, че номерацията на страниците в title tags за съответните страници няма да помогне на вашия сайт от гледна точка на неговата оптимизация. Това, което каза, е, че включването на номер на дадена страница в информацията относно самата страница ще има минимален ефект. Той допълни, че би го добавил само ако ще помогне на потребителите.
Google може да игнорира скрит текст на страница във вашия сайт
John Mueller от Google заяви в Twitter, че системите на Google могат да откриват скрит текст, да го разпознават и да го игнорират. Това означава, че най-вероятно няма да наложи санкции на вашия сайт, ако поради една или друга причина има такъв скрит текст на някои от вашите страници.
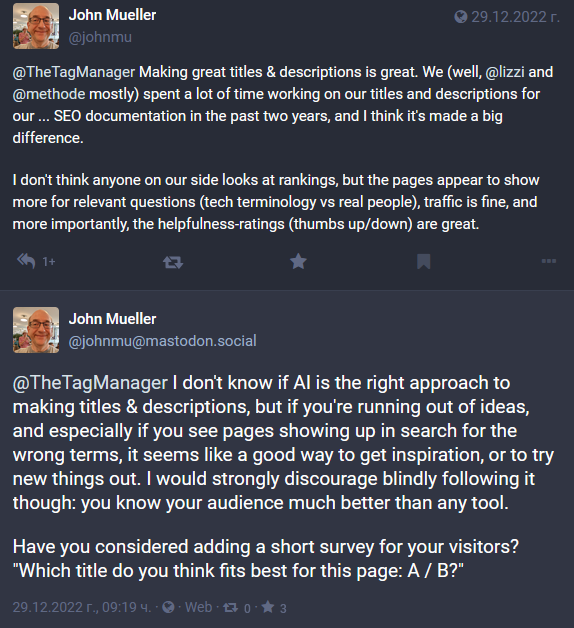
Можем ли да се доверим на изкуствения интелект и ChatGPT за идеи при създаване на title tags?
В Mastodon John Mueller коментира, че сляпото използване на ChatGPT и изкуствения интелект за генериране на title tags не е никак добра идея. В случай, че имате нужда от малко вдъхновение, инструментите, базирани на AI, биха могли донякъде да помогнат, но не и изцяло да им се доверите.
Той допълни, че създаването на заглавия и описания е важно, споделяйки, че екипът на Google е прекарал много време в създаването на такива за SEO документацията, която публикува.
Google направи актуализация на своя документация
Google актуализира документацията си Learn About Article Schema Markup, като премахна ограничението за създаване на заглавия до 110 символа. Вместо това Google съветва да се стараете да използвате кратки заглавия, тъй като са по-добре работещи от дългите, които може на някои устройства да бъдат съкратени.
Google: Core Web Vitals не са изискване на Google Discover
Един често задаван въпрос е това дали скоростта на сайта трябва да е изключително висока, за да може да влезе в Google Discover или URL адресите трябва да са изрядни в Core Web Vitals за целта.
На такъв въпрос в Mastodon John Mueller отговори, че Google не е документирал да има някаква връзка между Core Web Vitals и Google Discover, като допълни, че това би го изненадало. Или с други думи не е задължително условие, за да може вашият сайт да влезе в Google Discover и няма никаква връзка между двете неща.
Отчетът за Crawl Stats не показва какво е местоположението на обхождащия Googlebot
Интересен факт е, че Googlebot вече може да обхожда от места, които са извън САЩ. А ако искате да разберете какво е местоположението, от което Googlebot обхожда вашия сайт, то няма да може да получите тази информация през Google Search Console. За целта трябва да проверите лог файловете си.
Нова секция в помощната документация Crawl Budget Management
Google добави нова секция с името “Specify content changes with HTTP status codes” в помощната си документа Crawl Budget Management.
В този раздел Google пише, че поддържа хедърите на HTTP заявките “If-Modified-Since” и “If-None-Match” за целите на обхождането на вашия сайт. Google допълва, че crawlers не изпращат тези хедъри при всеки един опит за обхождане, като това зависи от случая за използване на заявката.
Какво се казва в доклад с изследване на Google?
Google има доклад с направено проучване, носещ името Generative Models are Unsupervised Predictors of Page Quality. В него една от подточките, “Frequent Terms Analysis”, Google описва, че документи, чиято цел е основно оптимизация, биват разглеждани като нискокачествени.
Причината за това е, че често се наблюдава как такива текстове се опитват да свързват поредица от ключови думи. Това прави съдържанието непоследователно и се възприема повече като текст, съставен единствено с цел SEO.
Google актуализира своя JSON файл
През месец януари Google направи актуализация на JSON файла, в който можете да откриете всички IP адреси на Googlebot. Това, което промени в него, е, че добави два нови IP адреса, които са:
- {„ipv6Prefix“: „2001:4860:4801:93::/64“}
- {„ipv4Prefix“: „66.249.74.128/27“}
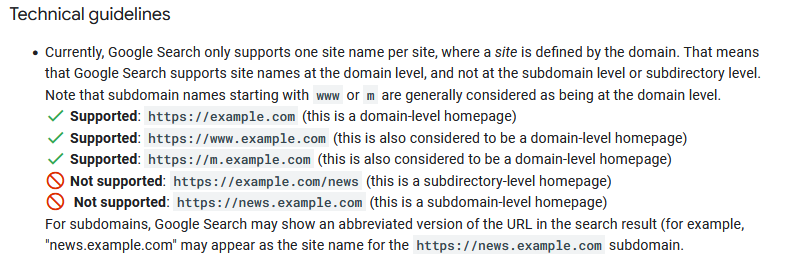
Какво трябва да знаете за m-dot и www- домейните?
Google актуализира своята документация за имена на сайтове, чието име е Site Names in Google Search. В нея Google обяснява, че префиксите m-dot (m.example.com) и www (www.example.com) се приемат за root domains. Към това допълни, че тези два префикса заедно с тези, които не сa www, Google ги счита за начална страница на ниво домейн.
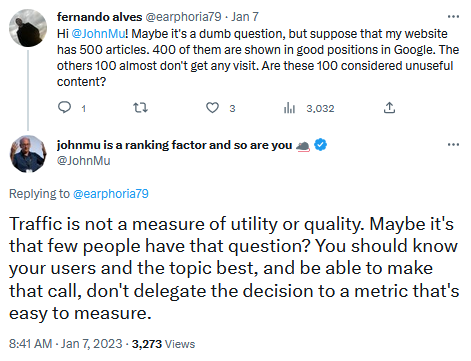
Google: Трафикът не е критерий за качество на търсенето
John Mueller от Google заяви в Twitter, че трафикът на вашия сайт не е фактор за качество. Той сподели, че само защото определен брой страници не получават толкова голям трафик, колкото други страници, не означава непременно, че тези страници са по-качествени или не за Google Search.
John допълни, че по-важното е да познавате вашите потребители, както и темите, по които можете да дадете експертиза и полезна информация. Всъщност той не за първи път потвърждава, че трафикът не е критерий за качество.
Това, което е споделял, е, че използването на трафика като критерий за качество, не е най-работещият метод за измерване качеството на съдържанието във вашия сайт.
Връзките към много доставчици в отзивите за продукти може много малко да помогне при класирането
При последната актуализация на Product Reviews, Google добави, че връзките към много продавачи е част от целия алгоритъм. В тази връзка Alan Kent от Google сподели в Twitter, че препратките към много доставчици може да помогне за подобряване на класирането, но влиянието, което ще окаже, ще бъде малко.
Google препоръчва да поддържате чиста HTML Head частта
John Mueller сподели, че когато говорим за HTML Head секцията, е важно да се уверим, че е чиста и синтаксисът не е нарушен, тъй като това може да наруши и други части от страницата и да попречи да бъде прочетена както от потребителите, така и от Google. Той допълни, че не трябва да се допуска да има JavaScript в тази секция.
Създаването на полезни SEO Case Studies е предизвикателство
Както знаете, Google споделя интересни SEO Case Studies, които предоставят полезна информация на всеки SEO специалист и собственик на уебсайт. Именно това каза и потребител в Twitter, отправяйки въпрос към John Mueller дали според него ще има нови. В отговор John каза, че за Google създаването на такива Case Studies е предизвикателство, особено предвид факта, че търсенето е изключително динамично.
Нова актуализация на Video Indexing Report
През месец януари Google съобщи, че е направил актуализация във Video Indexing Report. Промяната е в това, че Google Search Console ще може много по-добре да класифицира проблемите с индексирането на thumbnail. В резултат на това, ако съществуват такъв тип проблеми във вашия сайт, може да видите пренасочване на проблемите “Missing thumbnail” към по-конкретни типове проблеми.
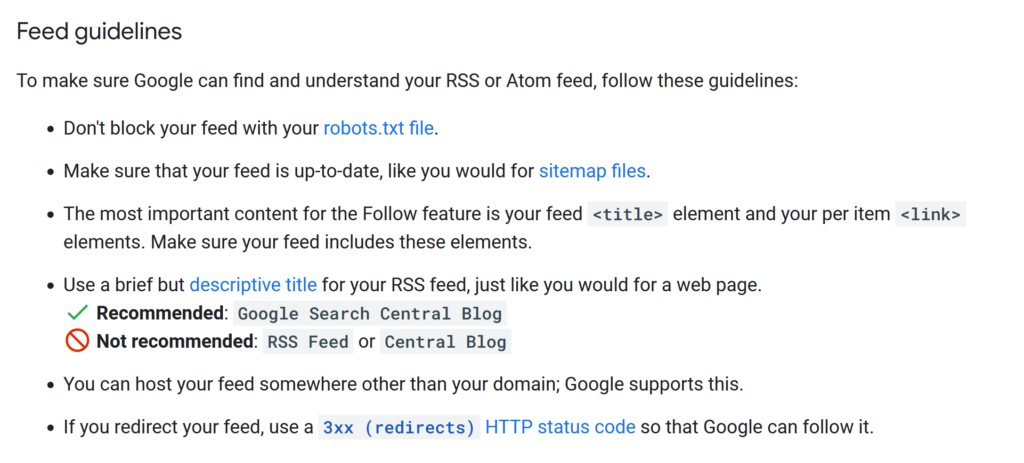
Google актуализира документацията Get on Discover
Още една актуализация, която Google направи, е тази в документацията Get on Discover. В нея Google добавя, че най-важното съдържание за функцията Follow са елементите < title > и < link >, затова е препоръчително винаги да проверявате дали присъстват и ако ги няма, да ги добавите.
Какво ново при най-добрите SEO практики за изображения от Google?
В документацията с най-добрите SEO практики за изображения, Google добави, че вече анализира елементите < img > в страниците ви, дори и в случаите когато те са затворени в други елементи, какъвто е < picture >. Към това допълва, че Google няма да индексира CSS изображения.
Добавяйте вашите canonical URL адреси в sitemap файла
Именно това ни напомни Gary Illyes от Google в LinkedIn, казвайки, че ако искате определени URL адреси да са canonical, трябва да ги включите в своя sitemap файл.
Той допълни в коментара си, че е напълно нормално да имате дублирано съдържание във вашия сайт, но е от съществено значение да “подсказвате” на Google коя страница искате да бъде canonical, т.е. да се показва в резултатите от търсенето в Google.
И именно sitemap е един от основните начини да кажете на Google кои са важните страници за вас и вашия сайт.
Честото публикуване във вашия сайт не е сигнал за спам
Една тема, която вълнува повечето SEO специалисти и собственици на онлайн бизнеси, е колко често е добре да се публикува ново съдържание и прекалено честото му публикуване не е ли сигнал за спам.
На този въпрос John Mueller каза, че честотата на публикуване на съдържание и неговия обем не са сигнал, по който Google определя дали вашето съдържание е спам или не е.
Към това той допълни, че ако има теми и полезна информация, които да споделите на вашите потребители, публикуването на ново съдържание дори и всеки ден е добре. А ако нямате, по-добре да не насилвате нещата, за да пишете всеки ден.
Google относно robots.txt и статус кода 4хх
Gary Illyes от Google сподели нещо полезно, което е важно всеки от нас да знае. В своя публикация той казва, че Google ще игнорира правилата на robots.txt, ако файлът ви е подаден със статус код 4хх. Като изключение посочи статус код 429.
Това е добро напомняне за всеки от нас да се увери дали нашият файл robots.txt е със статус код 200 и Google има достъп до него.
Представлява ли проблем, ако името на сайта ви наподобява това на друг сайт?
Такъв въпрос бе зададен на John Mueller и по-конкретно потребител обясни, че е открил друг сайт със същото име като неговия. Това, по което двата сайта се различават, е езика и темата, на която е самият сайт. Въпросът му бе дали това по някакъв начин е нарушение на правилата на Google.

В отговор John Mueller каза, че има много сайтове с подобни или същите имена на ниво домейн, което е напълно нормално и няма конкретни правила от страна на Google или забрани за използване на име на сайт. Към това той допълни, че от гледна точка на авторски права и всякакви правни въпроси няма как да помогне със съвет. Препоръките на John са да се обърне към адвокат.
Според Google генерирането на фалшиви URL адреси не би навредило на сайта
На въпрос, зададен в Mastodon, John Mueller отговори, че масовото генериране на фалшиви URL адреси на конкурентен сайт не би трябвало негативно да повлияе на този сайт, нито да доведе до проблеми от гледна точка на SEO.
Google публикува ново Case Study от Vimeo
Малко по-горе в този обзор споделихме с вас мнението на Google относно създаването и публикуването на Case Studies и това какво предизвикателство е. Малко след това през месец януари Google публикува ново case study от Vimeo. То е свързано с оптимизацията на видеа, а неговата тема е “How Vimeo improved Video SEO for their customers”. За тези от вас, които се занимават с оптимизация на видеа, тази публикация със сигурност би била интересна за разглеждане.
Не използвайте относителни URL адреси в rel-canonical
Това е съвет на Gary Illyes от Google, казвайки, че е препоръчително да използвате абсолютни URL адреси, а не относителни.
А ето и примера, който посочи:
<link rel=”canonical” href=”https://example.com/cats” />
Промяната на дизайна на вашия сайт може да доведе до промени в класирането му
Gary Illyes сподели още нещо важно, а именно че всяка промяна на дизайна на вашия сайт може да доведе до объркване на класирането му при търсене в Google.
Това, което сподели, е, че търсачките използват HTML файла на вашите страници, за да разберат съдържанието на тях. Когато прекалено много променяте семантиката в него, това може да промени изхода.
Разбира се това не означава да правите промени в дизайна, особено ако се опитвате да подобрите сайта ви от гледна точка на User Experience. А за да избегнете максимално проблемите и объркванията с класирането на вашия сайт, Gary Illyes посъветва да се опитате да използвате семантично сходен HTML и да избягвате добавянето на нови тагове в него.





