Обзор на Google – Март 2022

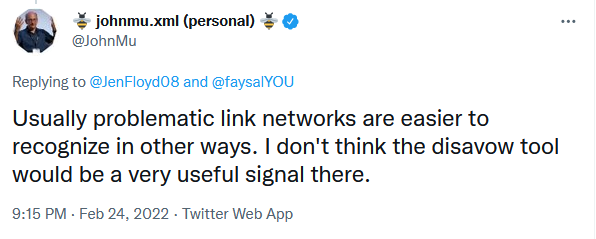
Google не използва файловете Disavow, за да насочва към мрежи от връзки
John Mueller от Google още веднъж сподели, че Google не използва файловете Disavow за откриване на мрежи от спам линкове. Той каза, че има много по-лесни начини за откриване и разпознаване на проблемни мрежи с линкове.
Google: Един сайт не винаги се класира над друг сайт
Имаше въпрос в Twitter, който бе отправен към John Mueller. В него се питаше дали има нещо специфично в това, ако статиите в Medium винаги се класират по-добре от статиите, открити в LinkedIn.
John отговори, че няма специално класиране при търсене за даден сайт. Не винаги сайт А се класира над сайт Б. Той допълни, че зависи от това какво търсите и какво смятате за релевантно за дадено търсене.
CSS цветовете не са фактор за класиране при търсене в Google
John Mueller заяви в Twitter, че Google не използва цветовете като фактор. Той допълни, обаче, че CSS промените могат да включват много повече неща от просто промяна на цвета.
Разбира се тук е важно да напомним, че това изказване се отнася само за цветовете. В случай, че решите да направите други промени с помощта на CSS, то това може да повлияе по един или друг начин на класирането ви в Google.
Такива промени могат да бъдат преместване или скриване на съдържание, както и промени в главната навигация и архитектура на сайта.

Google: Преведеното съдържание и ненужни параметри в URL адресите
Важно е да знаете, че можете да объркате Google в случай, че в URL адресите ви има ненужни параметри, особено когато това са параметри на преведено съдържание.
На тази тема беше и един от въпросите, отправени към John Mueller. Казусът бе свързан с многоезичен сайт, при който се е установило, че преведеното съдържание е изключено от индекса и в Google Search Console е със статус Crawled currently not indexed.
В отговор John каза, че това може да е свързано с параметъра в края на кода за език. Това, което най-често се случва е, че когато Google разпознава, че има много такива парамтри, които водят към едно и също съдържание, той може да помисли, че съдържанието не е полезно и да го игнорира.
Като съвет John Mueller препоръча използването на URL Inspection Tool в Google Search Console, като това ще помогне на Google да разберете, че дадените URL адреси трябва да бъдат индексирани. Друг начин е чрез използването на редиректи и чисти URL адреси.
Квотите за класиране в Google не съществуват
John Mueller сподели в Twitter, че няма каквато и да било квота и по-конкретно няма ограничен брой ключови думи, по които уебсайтовете могат да се класират. Това означава, че за Google няма лимит относно това колко точно на брой страници ще показват от даден сайт.
Но тук той допълни една важна тема, а именно, че борбата за класиране на няколко ваши страници по едни и същи ключови думи е сложна. Това често се оказва не до там добра стратегия.

Актуализацията на Google Page Experience за настолни компютри приключи
Ако си спомняте, в предходния обзор на Google за месец февруари, споделихме, че стартира актуализацията на Page Experience за настолни компютри. Този месец тя приключи и десктоп версията е вече налична в отчета Page Experience.
Филтърът SafeSearch е възможно да се актуализира по-бързо
Филтърът SafeSearch, който се грижи за това да премахва нецензурирано съдържание обикновено много бавно се актуализира. На първата за месец март петъчна SEO среща John Mueller сподели, че екипът на Google направи някои стъпки, за да подобрят този филтър, така че при промяна той да се актуализира много по-бързо от сега.
Google: Проблемите с индексирането могат да са свързани със стар спам, но не и със съдържание за възрастни
Ако забелязвате, че има страници от вашия сайт, които не са индексирани от Google, то причините за това могат да са много. В тази връзка John Mueller заяви, че ако дадена страница във вашия сайт е имала старо спам съдържание, което вие сте премахнали, то може все още да имате проблем с индексирането.
Всичко това означава, че на Google може да му трябва време, за да се довери на домейн, който има история за спам съдържание. Това е така, защото Google не харесва спам и неведнъж е казвал, че проблемите с индексирането могат да са свързани с проблеми с качеството на целия ви сайт.
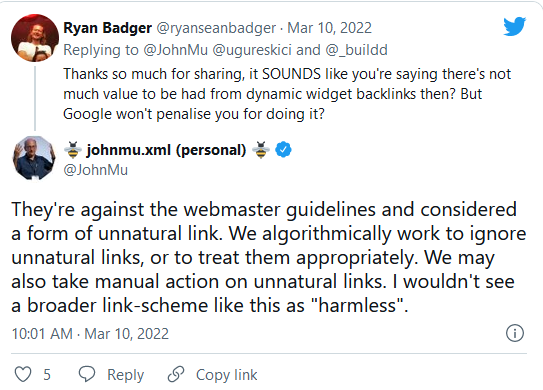
Google: В повечето случаи игнорираме widget връзките и не наказваме
Накратко, Google има помощна документация, която е срещу така наречените widget връзки. Но още 2017 година John Mueller бе казал, че Google най-вероятно автоматично ще игнорира този тип линкове. Това означава, че ще ги третира като nofollow.
John отново написа в Twitter, че за Google тези линкове нямат стойност и потвърди, че е против правилата за уебмастъри. Той добави, че те се считат за ненатурални връзки. Google алгоритмично игнорира този тип връзки или ги третира по подходящ начин.
Освен това каза, че Google може да предприеме и ръчни действия с тези линкове и заключи, че не намира този тип схема за “безобидна”.
Danielle Marshak от Google говори за това как търсачката разбира видеоклиповете
В последния подкаст на Google Search Off the Record на Gary Illyes и Lizzi Sassman, които са част от екипа на Google Search Central, гостува Danielle Marshak. Тя е продуктов мениджър на Google Search за видеоклипове.
Един от въпросите, които Gary Illyes зададе по време на подкаста е как Google разбира какво има в даден видеоклип. В отговор Danielle Marshak сподели, че Google извлича текста, а разбирането на видеоклиповете е възможно по няколко начина:
- може да се използва звука, за да се разбере какви думи се изричат;
- символите могат да бъдат извлечени от видеоклипа, което включва заглавия – това помага да се разберат важните моменти;
- може да се извлече визуална информация като обекти, животни или движения – към това Danielle Marshak допълни, че това е една от най-трудните задачи за Google;
- по няколко начина се използват структурираните данни – това означава, че е важно да използвате структурирани данни. Те се използват за откриване на видеото и за получаване на видео съдържанието.
Google: Използването на hreflang не повишава класирането на вашия сайт
На въпрос в Twitter John Mueller заяви, че използването на hreflang не подобрява класирането. Въпреки това, атрибутът е важен за сайтовете, които използват няколко езика, тъй като помага на Google да разбере по-добре вашия сайт.
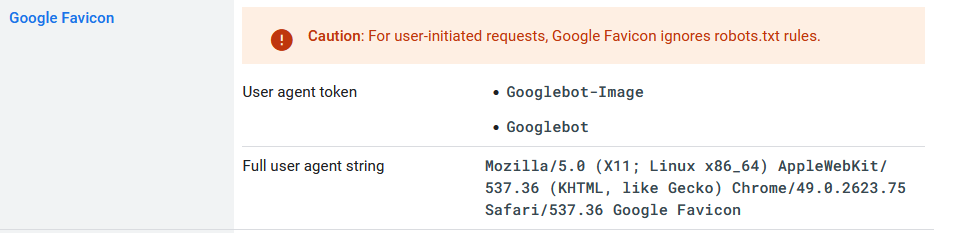
Google Favicon Crawler използва Googlebot и Google-Image Token
През месец март Google актуализира помощната си документация, свързана с ботовете, които обхождат сайтовете. В тази връзка Google съобщи, че Google Favicon спазва правилата на ботовете Googlebot и Googlebot-Image. Досега обхождащия бот спазваше единствено и само собствени правила.
Google: Не използваме ангажираността на потребителите като фактор за класира при търсене
На втората за месец март English SEO Office Hours hangout John Mueller каза, че Google не използва така наречения engagement като фактор за класиране или за някакви други цели при търсене в Google. Той допълни, че би обърнал внимание и би бил по-внимателен относно заявките, по които се показват дадени страници от вашия сайт. И по-конкретно, дали тези заявки са релевантни на резултата от търсенето в Google.
Метриките на актуализацията на Google Page Experience могат да бъдат разделени на части от сайта ви
От гледна точка на актуализацията на Page Experience и показателите в отчета, то трябва да споделим с вас, че Google може да раздели показателите на няколко различни секции.
Така, например, метриките от сайта ви могат да се делят според типа страници – категорийни страници, страници с продукти – а може да се разделят според структурата на вътрешните линкове. За целта, обаче, Google трябва да разполага с достатъчно данни от вашия сайт.
Временното покачване на позициите при класиране и след това спадане е проблем с качеството
На една от петъчните срещи SEO специалист сподели, че сайт, по който работи има проблем с класирането. Той не се е класирал добре, заради което решават да направят миграция на сайта към нов домейн. След направената миграция сайтът е повишил своите позиции за три дни, но след това отново се е върнал на старата си позиция.
В отговор на това John Mueller сподели, че най-вероятно е свързано с качеството на сайта. Това, което той обясни е, че след направена миграция на Google са му отнели няколко дни, за да разбере, че сайтът е бил преместен, съответно е последвало покачване в класирането. Но, след това, той е приложил сигнали за качество и в резултат е разбрал, че качеството продължава да е ниско, затова и сайтът се е върнал на долни позиции.
Google: Имплементирането на Google Analytics 4 няма да донесе до повишаване на класирането при търсене
На въпрос в Twitter John Mueller заяви, че Google няма да повиши позициите на даден сайт при търсене в Google само защото е преминал към Google Analytics 4.
Преместването на сайтове с редиректи в рамките на 3 месеца е твърде кратък период
Именно това беше отговорът на Google и по-конкретно на John Mueller от Google. Той допълни, че тези редиректи трябва да се поддържат в продължение на по-дълъг период. Той препоръча да се запази старото име на домейна за по-дълго време и да се запазят редиректите поне за една година.
Google: Съдържание, което е генерирано от машини или изкуствен интелект, не се счита за качествено
През последните няколко години Google говори за това, че ако съдържанието, генерирано от машини или изкуствен интелект стане висококачествено, то Google може да позволи да бъде част от насоките за уебмастъри. Но това все още не е факт.
И този месец John Mueller сподели, че такъв тип съдържание не се счита за висококачествено. В Twitter той направи коментар, че повечето сайтове изпитват проблем със създаване на висококачествено съдържание.
Google относно това защо не индексира абсолютно всеки URL адрес в един сайт
John Mueller обясни защо Google не индексира всеки един URL адрес във вашия сайт. Това, което той сподели е, че на теория е много трудно да се обходи всичко в един сайт, тъй като броят на URL-ите е безкраен. Освен това никой не може да си позволи да съхранява безброй много URL адреси в бази данни, тъй като би струвало много скъпо.
Нещо повече, той обясни, че интернет няма необходимата свързаност и бързина, което е още една пречка за обхождане на абсолютно всичко.
Има страници, които динамично се променят, докато други са такива, каквито са били преди 10 години. Това прави ненужно постоянното обхождане на тези страници. Именно затова и ботовете се опитват да спестят време и усилия, фокусирайки се, върху страници, които се променят.
John обясни, че има много спам страници и такива, които не предоставят нищо полезно. Те могат да имат приемливи линкове, но все още да не са добре справящи се. Има немалък брой на сайтове, които от техническа гледна точка са добре, но все още им липсва необходимото качество.
Това са и едни от основните причини ботовете на Google да не обхождат постоянно. Те работят с опростен набор от URL адреса, като преценяват каква да бъде честотата на обхождане, на какво да наблегнат и какво да игнорират.
Какво ново в отчета за богати резултати в Google Search Console?
Google публикува известие, в което казва че ще показва предупреждения, когато вашите структурирани данни не определят местоположението на дадено събитие. Тези предупреждения ще са видими в отчета с богати резултати в Google Search Console.
Към това допълни, че ще започне да изисква местоположението на дадени събития. Това, което каза е, че за събития, които са отбелязани само като виртуални (т.е.eventAttendanceMode=OnlineEventAttendanceMode), предоставянето на физическо местоположение ще предизвиква warnings.
В случай, че има физически адрес, то той трябва да бъде тип Place, а не PostalAddress. В противен случай това ще се отчете като грешка. Необходимо е да бъдете внимателни, тъй като това може да доведе до значително увеличаване на грешките или предупрежденията.
Дали пренасочването на линкове, които водят към страници със статус 4040,ще има стойност за Google от гледна точка на SEO?
Както знаем, линковете, които сочат към несъществуващи страници, т.е. такива, които са със статус 404, не се вземат предвид от Google. Но днес John Mueller говори за това, че има случаи, когато можете да пренасочите стари страници, които са 404.
Той допълни, че има вероятност, ако линковете са много стари, Google да не им обърне внимание, но съществуват и обратните варианти. И все пак по препоръки на Google може да се опита за целите на SEO.
Google премахва URL Parameter Tool в Google Search Console
Google обяви, че от 26 април премахва URL Parameter Tool, който към момента е част от Google Search Console. Към това допълни, че потребителите не е необходимо да предприемат каквито и да е било допълнителни действия.
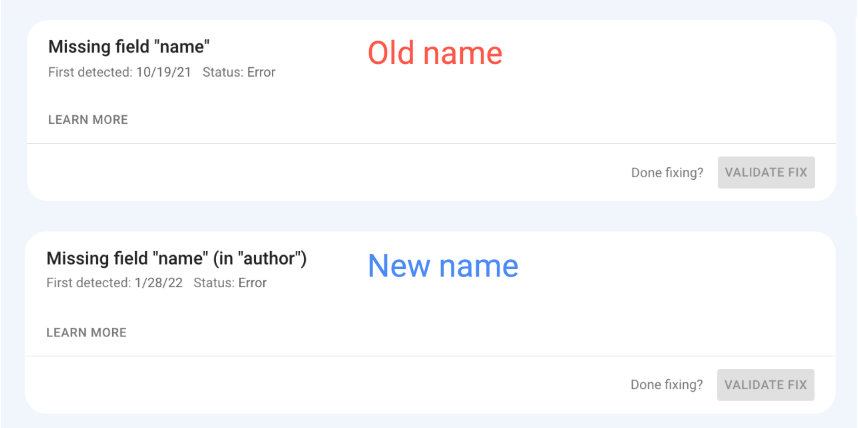
Отчитането на грешки в структурираните данни в Google ще бъде с по-описателни имена
Google въведе нови по-конкретни и по-описателни наименования на съобщенията за грешки в структурираните данни в отчетите rich results status, URL Inspection Tool и Rich Result Test, които са част от Google Search Console.
В тази връзка Daniel Waisberg от Google написа в Twitter, че няма от какво да се притеснявате, тъй като промяната е свързана единствено и само със самите имена.
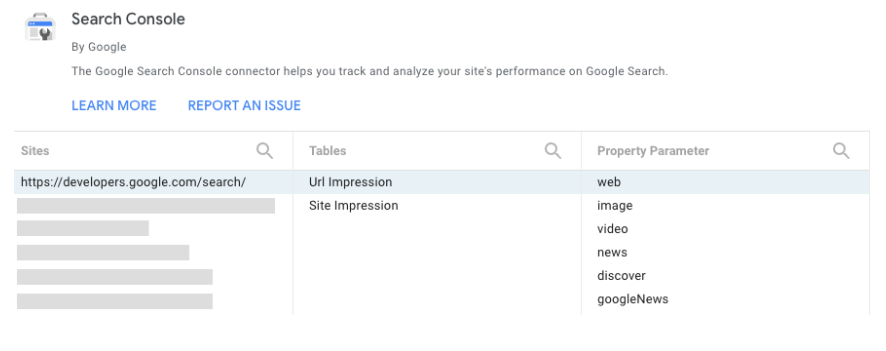
Google Data Studio ще поддържа трафика на Discover и Google News в Search Console
Google обяви, че конекторът на Google Search Console за Google Data Studio може да въвежда данни за трафика на Google Discover и Google News. Благодарение на това вие ще можете да комбинирате повече данни директно в Google Data Studio.
Ето и как изглежда Google Search Console connector:
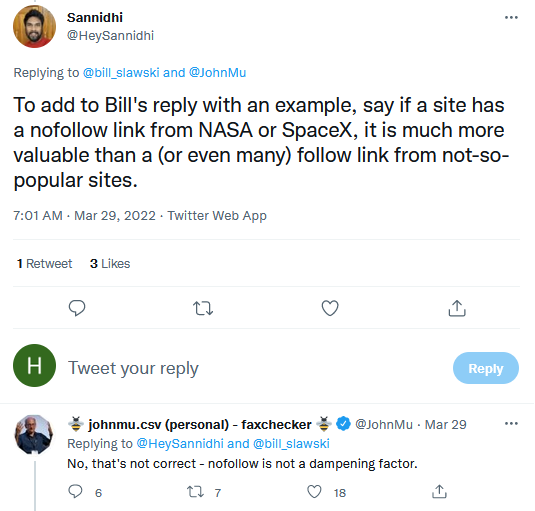
Google: Линковете nofollow не е фактор за намаляване на стойността на връзката
John Mueller от Google сподели в Twitter, че линковете nofollow не фактор, който би намалил стойността на даден линк.