Обзор на Google – Октомври 2020

Изпращането на URL адреси не води до Google да преработи вашите Sitemap
Джон Мюлер от Google заяви в Twitter, че ако използвате URL адреса за изпращане в Google Search Console, това няма влияние върху Google при преработката на вашия XML файл с карта на сайта. Той каза, че Google просто обработва редовно този XML файл с карта на сайта, така че там няма какво да правите.
Google споделя детайли по отношение на съгласието за бисквитки, влияещи на кумулативното изместване на оформлението
Един от елементите сред основните важни показатели за оценка на скоростта, който е част от предстоящата актуализация на Google Page Experience, е Cumulative Layout Shift (CLS). Има някои твърдения, че лентите за съгласие на бисквитки оказват влияние върху оценката на кумулативното оформление на сайта. Към момента Гугъл все още събира обратна връзка, за да прецени това дали е така и има ли по-нататъшно влияние или не.
Google: Премахването на връзки може да повлияе на класирането ви, но връзките не са единствената причина да класирате
Джон Мюлер от Google в Twitter заяви нещо очевидно, но каза, че „Връзките са причината сайтът да се класира по-високо, а след това ако ги премахнете, сайтът ще се класира по-ниско“. Но след това добави, че „връзките не са единствената причина сайтовете да се класират“. По този начин той каза: „Не бих се фокусирал сляпо върху тях. Не бих омаловажавал и връзките – те са склонни да бъдат важен сигнал за класиране за Google и други търсачки.“
Кога Google Search Console може да покаже идентификатори на фрагменти на URL адреси?
Понякога виждате в отчета си на Google Search Console, като отчета за ефективността, идентификатори на фрагменти на URL адреси. Знаете URL адресите със знаците # в тях. Видяхме ги, когато Google тестваше показване фрагментно превъртане и акценти в Search Console. Те могат да се показват и за някои връзки към сайта.
Google разкрива политиките за Web Stories, най-добри практики и примери
Google публикува в своята документация за разработчици нови документи около Web Stories. Тези нови документи стартираха с пускането на уеб истории в Google Discover, но те се прилагат по-широко за всички употреби на уеб истории в Google.
Политиките за уеб истории казват „за да се показват вашите уеб истории в Google Discover и Търсене като единични резултати, те трябва да отговарят на правилата на Google Discover и насоките на Google за уеб администратори. За да могат уеб историите да се появяват на по-богат опит в Google (например изглед в мрежа) за Търсене, Google Изображения и въртележка в Google Discover), Web Stories трябва да спазват следните правила за съдържанието. В случаи на груби нарушения на Политиките за съдържание на Web Stories, сайтът може да спре да се показва за постоянно в по-богатия опит в Google. “
Правилата четете тук: https://developers.google.com/search/docs/guides/web-stories-content-policy#:~:text=Web%20Stories%20are%20meant%20to,Stories%20to%20appear%20across%20Google.
Google Gary Illyes обяснява какво прави Caffeine

Google пусна следващия следващ подкаст Search Off the Record, който всъщност беше записан преди поне два месеца, Gary Illyes от Google разби митовете какво прави всъщност индексът и системата на Google Caffeine.
„Имаме Caffeine. Това е нашата система за индексиране. Само външно се нарича Caffeine. Вътрешно тя има друго име. Но това всъщност няма значение. И прави много неща. И мисля, че това не е много ясно отвън, че прави много неща. За хората това е точно като ние имаме робот, който е Googlebot, и след това преминава към нещо, което е Google магия. Е, хората знаят, че се визуализира, а след това нещо, което е Google магия, имаме индекс.
Всъщност не можем да разбием магия на Google и хората като цяло знаят за тази магия на Google или биха могли да разберат, ако искат, но магията на Google е по същество това, което прави Caffeine. По принцип поглъщането, събирането на всичко, произведено от Googlebot, е буфер на протокол – можете да го потърсите в любимата си търсачка какво представлява буферът на протокола. И тогава този протоколен буфер се взима от кофеина и след това събираме сигнали, бла, бла, бла и след това добавяме информацията, която кофеинът произвежда в нашия индекс.
Какво се случва вътре в кофеина? Е, първата стъпка е поглъщането на буфер на протокол. По принцип той взима буфера на протокола и започва да го обработва. Първата стъпка след поглъщането е преобразуването.
Но все пак се опитваме да го осмислим. Ако наистина сте счупили HTML, това е доста трудно. Така че ние прокарваме целия HTML през HTML lexer. Отново потърсете името. Можете да разберете какво е това. Но всъщност ние нормализираме HTML. И тогава е много по-лесно да го обработите. И тогава идва хотстеперът: h1, h2, h3, h4.“
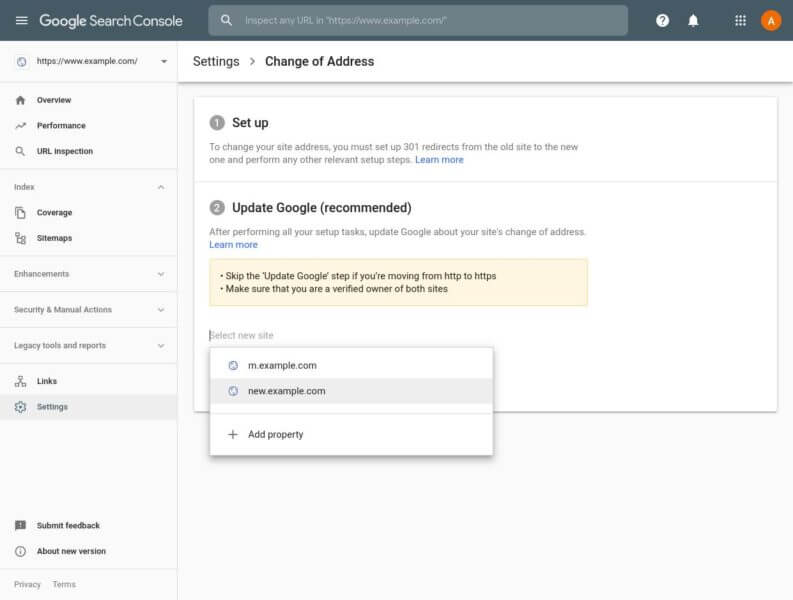
Инструментът за промяна на адреса на Google е настройка, а не проверка на състоянието
По-рано тази година Google актуализира инструмента за промяна на адреса, но може би новият инструмент прави нещата малко по-неясни? Когато извършите преместване на сайт, той ще ви каже „този сайт в момента се премества в …“ И това ще остане там дори след преместването на сайта.
Собственик на сайт попита Джон Мюлер от Google в Twitter „Какво би причинило заявката за промяна на адреса на даден сайт да остане с този статус в GSC за повече от година?“ Джон отговори, това не работи по този начин, той каза: „Това е по-скоро като настройка – това не означава, че нещата все още са в очакване или изпълнение.
Google: През повечето време грешната дата в резултатите от търсенето е ваша вина
Преди няколко години Google каза, че с дати и часове във фрагментите на резултатите от търсенето понякога те признават, че просто грешат. Но защо Google го разбира погрешно? Gary Illyes от Google заяви, че почти винаги можете да обвинявате уебмастъра / собственика на сайта, че Google е сгрешил датата.
Гари беше попитан защо Google ще показва грешна дата, когато всеки сигнал, който уеб сайтът дава, е правилната дата. Гари отговори в Twitter, казвайки, „но най-често това се случва, когато има огромни доказателства, показващи, че вие, собственикът на уебсайта, който е направил промяната, грешите.“
През март 2019 г. Джон Мюлер от Google написа дълга публикация в блога, наречена „Помогнете на Google Търсене да знае най-добрата дата за вашата уеб страница“. Така че има съвети, които да помогнат на Google да избере правилната дата.
Нo Google има проблеми с показването на точните дати във фрагментите. Google дори показа бъдещи дати във фрагментите преди и се знае, че има проблем, както казахме преди. Всъщност понякога се показват нереални дати, а понякога хората подвеждат Google, но сигналите, които Google използва за събиране на дати, не са перфектни и за тях е постоянен проект.
Google: Исканията за преразглеждане могат да отнемат седмица до няколко месеца
Въпрос, който често се появява в света на SEO, е колко време отнема, след като човек подаде искане за преразглеждане в Google Search Console, за да получи отговор. Тя може да варира и по-рано тази година изглежда имахме няколко изоставания там, но Джон Мюлер от Google заяви в Twitter „няма определено време за обработка на искане за преразглеждане“.
Тогава Джон каза, че „понякога е седмица или нещо повече, понякога е няколко месеца“. Защо едно ще отнеме повече време от следващото? Той каза, че няма причина. Той каза: „Това не зависи от това дали сте купили домейна наскоро (и виждаме много опити за злоупотреба с изтекли домейни, така че не означава, че е по-лесно).“
Google тества свързани търсения отгоре
Изглежда, че Google тества поставянето на свързаната функция за търсене в горната част на страницата с резултати от търсенето, за разлика от долната част на страницата с резултати от търсенето.
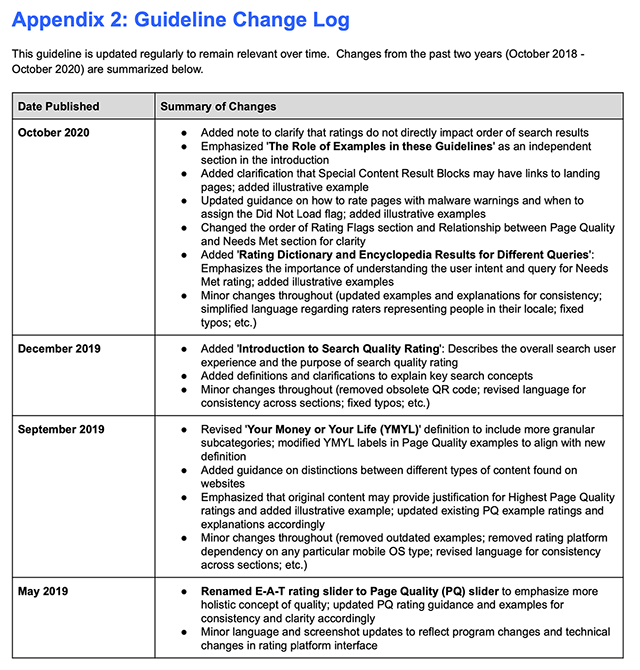
Google актуализира Search Quality Raters Guidelines на 14 октомври
Google добави раздел „Дневник на промените“ на последната страница, страница 175. Ето промените:
- Добавена бележка за пояснение, че рейтингите не влияят пряко върху реда на резултатите от търсенето.
- Подчерта „Ролята на примерите в тези насоки“ като независим раздел във въведението.
- Добавено разяснение, че специалните блокове с резултати от съдържанието могат да имат връзки към целеви страници; добавен илюстративен пример.
- Актуализирани указания за това как да оценявате страниците с предупреждения за злонамерен софтуер и кога да присвоите знамето „Не се зарежда“; добавени илюстративни примери.
- Промени в реда на раздела с рейтингови флагове и раздел „Връзка между качеството на страницата и нуждите за постигане на яснота“.
- Добавен „Резултат от речника на рейтинга и енциклопедията за различни заявки“: подчертава значението на разбирането на потребителското намерение и заявка за оценка на нуждите; добавени илюстративни примери.
- Незначителни промени през цялото време (актуализирани примери и обяснения за последователност; опростен език по отношение на оценителите, представляващи хората в техния локал; фиксирани печатни грешки и др.).
Google: Първото индексиране за мобилни устройства трябва да бъде индексиране само за мобилни устройства
Така че вчера по време на основната беседа на Джон Мюлер в PubCon той обобщи обявеното през годината около промените в SEO в Google. Едината беше относно промените в мобилното индексиране и крайния срок. Това предизвика известно объркване сред SEO индустрията, която се нуждае от разяснения.
Google за първи път стартира тази инициатива и първо индексиране за мобилни устройства през 2016 г. Когато Google за първи път я стартира, Google заяви, че ще започне процеса на обхождане на мрежата от гледна точка на мобилния телефон на първо място. Истината е, че Google рано каза, че вашата работа е да се уверите, че вашият десктоп и мобилен сайт са синхронизирани; в синхрон със съдържание, схема, връзки и т.н. Защото, когато сайтът ви е обходен с помощта на първоначално индексиране за мобилни устройства, Google ще се съсредоточи върху мобилния сайт и почти ще игнорира вашата настолна версия.
Но хората по някаква причина смятаха, че Google ще продължи да обхожда и индексира версията за настолни компютри, в допълнение към мобилната версия. Това не е вярно, освен ако Google не проверява за спам и манипулация. Но като цяло не, Google просто ще обхожда с помощта на мобилния потребителски агент, а не на работния плот. Имайте предвид, че по-голямата част от индексирането на Google днес се извършва чрез мобилно индексиране, а не на настолни компютри.

Google спира функцията за индексиране на заявки, докато има проблеми с индексирането
Google обяви, че временно е спрял функцията за индексиране на заявки в рамките на инструмента за проверка на URL адреси в Search Console. Не се казва защо, освен да се правят промени в инфраструктурата. Но това идва в лош момент, тъй като много сайтове се оплакват от проблеми с индексирането с Google Търсене.
Google написа в Twitter „Деактивирахме функцията„ Заявка за индексиране “на инструмента за проверка на URL адреси, за да направим някои промени в инфраструктурата. Очакваме да се върне през следващите седмици. Продължаваме да намираме и индексираме съдържание чрез нашите редовни методи. „
Google ще отхвърля продуктите, които не са налични, от подаването на данни, когато са налични на място
Google обяви, че ще започне „предварително да одобрява безплатните стандартни списъци за продукти, които са маркирани като изчерпани в данните за продуктите в Merchant Center, но са налични на техните целеви страници“. Не мисля, че това се отнася за платени листинги, а само за безплатни листинги.
Така че, ако изпратите емисия за данни и в нея има продукти, които са обозначени като изчерпани, но целевата страница на вашия уеб сайт ги показва като налични – Google няма да ги одобри.
Google каза „за да избегнете предварителното неодобрение на вашите продукти, уверете се, че стойностите за наличност на данните за продуктите ви в Merchant Center точно отразяват наличността на всеки продукт на съответната му целева страница. Препоръчително е да активирате автоматични актуализации на артикули в профила си в Merchant Center, за да намалите вероятността от несъответствия. “
Ако искате да изключите продукти от списъците си, използвайте атрибута exclu__destination.

Обяви за търсене в Google: BERT, пасажи и индексиране на подтеми и други

BERT
BERT вече се използва за почти всяка английска заявка. Както знаете, когато стартира преди година, той беше използван при 10% от английските заявки. Google заяви „днес сме развълнувани да споделим, че BERT вече се използва в почти всяка заявка на английски, което ви помага да постигнете по-висококачествени резултати за вашите въпроси.“ Няма какво наистина да направите, за да оптимизирате в SEO за това, но Google трябва да бъде по-добър в разбиране на вашето съдържание и как то е свързано с заявката на потребителя.
Правопис
Google заяви, че има нов алгоритъм за правопис, който използва „дълбока невронна мрежа, за да подобри значително способността ни да дешифрираме правописни грешки“. Google каза, че тази промяна „прави по-голямо подобрение на правописа от всички наши подобрения през последните пет години“.
Проходи
Google вече може да индексира части от страница, пасаж в цялото съдържание на страницата, вместо цялото съдържание на страницата. Преди това Google каза, че не го прави и не може да го направи, но сега може. Google каза „наскоро направихме пробив в класирането и вече можем да индексираме не само уеб страници, но отделни пасажи от страниците“.
Google заяви, че това им помага да подобрят заявките за търсене в световен мащаб, на всички езици, и ще повлияе на 7% от резултатите от търсенето! Това им помага да разберат по-добре релевантността на конкретни пасажи, а не само на общата страница.
Разграничението е важно, тъй като сме обсъждали преди това, че Google не индексира части от страница – той индексира цялата страница и след като е индексиран, той определя как да използва съдържанието на страницата в класирането.
Подтеми
Google също заяви, че „прилага невронни мрежи за разбиране на подтеми около интерес, което помага да се осигури по-голямо разнообразие на съдържание, когато търсите нещо широко.“ Google заяви до края на годината, че „ще разбере подходящи подтеми, като бюджетно оборудване, първокласни снимки или идеи за малки пространства, и ще покаже по-широк набор от съдържание за вас на страницата с резултати от търсенето“.
Google Search Console изпраща известия за откриване на съвети за оптимизация за Google Discover.
Google изпрати наскоро куп известия чрез Google Search Console, за да уведоми някои издатели, че пропускат трафика на Google Discover. Google е изпращал известия от Search Console за Google Discover и преди, но този път в това известие се казва, че пропускате потенциалния трафик на Google Discover.
По-конкретно, препоръчва на тези издатели да използват настройката за метамаркиране на роботи за максимален преглед на изображения, за да подадат на Google по-големи изображения, за да могат да бъдат използвани в Google Discover.
Google казва, че връзките в коментиран HTML не влияят на класирането
Мартин Сплит от Google, в рядък случай, когато говори конкретно за класацията на Google, каза, че потвърди, че докато Google може да открива връзки в коментиран HTML код, тези връзки не се използват за целите на класирането в Google.
Google: На страницата няма оптимален брой връзки
В продължение на това, че Google казва, че имат глупав висок лимит за броя на връзките, които може да извлече от дадена страница, Google също казва, че няма оптимален брой връзки, които трябва да имате на дадена страница. Джон Мюлер от Google беше попитан за това и той отговори в Twitter, казвайки, че „на страницата няма оптимален брой връзки.“
Google: Спирането на заявките за индексиране не есвързано с бъгове при индексирането
Както много от вас знаят, Google спря (временно) функцията за индексиране на заявки в Google Search Console. Това се случи по времето, когато Google имаше множество текущи проблеми. Google отстрани тези проблеми с индексирането, но инструментът за индексиране на заявки все още не е активен. Google заяви, че двете не са свързани.
Google игнорира изписването с главни букви в HTML
Дали главните букви в HTML кода създават проблеми с Google? Отговорът е не, Google очаква тези грешки при писане и тъй като работи в браузър, работи и за Google Търсене.
Джон Мюлер от Google беше попитан за това в Twitter И той каза „изписването с главни букви в имената на атрибути на HTML се игнорира (напр. В XHTML те често са изцяло с главни букви)“. Той добави, че има смисъл да го правим с малки букви и да бъдем последователни“.





