Обзор на Google – Ноември 2020

Google за Passage Indexing: Това не е основна актуализация, класирането не е индексиране и не оптимизирайте за него
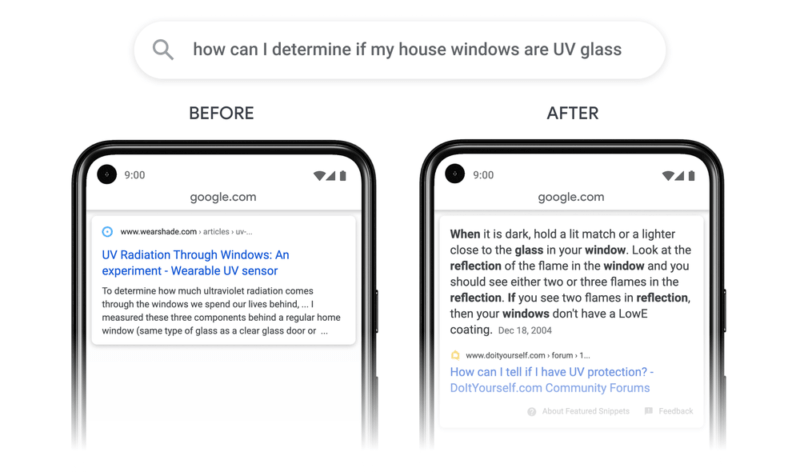
Джон Мюлер от Google по темата за Passage Indexing отговори, че тази промяна на индексирането на параграфи не е (1) не основна актуализация, (2) не е за индексиране и (3) не е нужно да оптимизирате за него.
Passage Indexing не е основна актуализация
Джон каза: „Това не е основна актуализация. Искам да кажа, че не бихме го разгледали като основна актуализация. Мисля, че основната актуализация така или иначе е някакъв произволен термин, но не е това, което бихме помислили за основна актуализация.“
Класиране, не индексиране
Открихме, че промяната в индексирането на параграфи не е свързано с индексиране, а с безкрайно класиране. Но Джон повтори, че „по-скоро става въпрос за класиране на тези пасажи от съществуващи страници, а не за индексиране по отделно. Така че повече за разпознаването на това дали дадена страница е голяма, дали дадено съдържание е част от страницата и то е подходящо за заявка, която идва , така че Google ще се съсредоточи върху тази част от страницата. Това не означава, че има отделен индекс за параграфи. Това наистина е по-скоро за разбиране на страницата и различните части на страницата и за разпознаване на коя от тези части са от значение за заявката на потребителите. “
Оптимизиране за индексиране на пасажи
„Като цяло, с много от тези промени, едно нещо, от което бих се предпазил, е да се опитам да оптимизирам за тези неща.“ Джон обясни, че няма „много повече подробности за споделяне“ по този въпрос, но каза, че има „хора, които са анализирали патенти и документи“, като историята на Даун Андерсън като пример.
Накратко, така или иначе трябва да имате добре структурирани страници. Тази актуализация просто позволява на Google да разбере структурата на по-дългите страници. Няма информация, че Google ще бъде по-добър в разбирането на параграфи на по-дълги страници. Просто това ще са прихванати от Google параграфи, на която и да е уеб страница, добре или лошо структурирана.
Джон добави „Много от промените, които правим като тези са, защото забелязваме, че уеб страниците са някак разхвърляни и неструктурирани. И не е толкова, че тези разхвърляни и неструктурирани уеб страници изведнъж имат предимство пред чисти и структурирани страници. По-добре можем да разберем тези объркани страници горе-долу по същия начин, както можем да разберем добре структурираните страници. Така че, ако вземете чиста страница и се опитате да я направите объркана, така че да работи добре за този нов вид настройка, тогава не мисля, че бихте имали някакво предимство пред това, което сте имали преди. „
Какви са очевидните съвети за SEO? Джон каза „Чисти заглавия, подзаглавия и т.н. Той каза „къде, ако вече имате чисти страници, ако те вече са лесно разпознаваеми от търсачките, ако те имат чисти заглавия и подзаглавия и те се фокусират върху отделни теми, това е по същество това, което търсачката трябва да може да разбере за какво става въпрос на тази страница и кога да я покаже на потребителите. „
Google ще спре да поддържа Data-Vocabulary на 31 януари 2021 г.
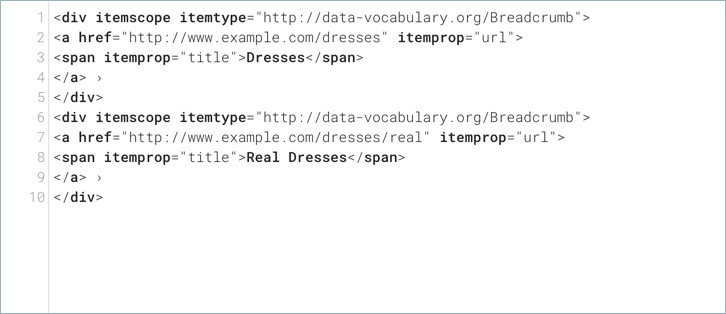
Преди седмица съобщихме, че въпреки че Google ни каза, че ще прекрати поддръжката на data-vocabulary.org миналия 6 април 2020 г., след това я измести към юни 2020 г. Но това дойде и си отиде и Google все още го поддържаше.
Google написа в Twitter в петък следобед „Моля, обърнете внимание – от 31 януари 2021 г. маркирането на http://data-vocabulary.org ще спре да отговаря на условията за функции и подобрения на резултатите от търсенето с Google“ Google актуализира оригиналната публикация в блога в горната част, за да добави „Актуализация на 2020-10-30: Ще отхвърлим поддръжката за data-vocabulary.org на 29 януари 2021 г. Това означава, че това маркиране ще спре да отговаря на условията за резултатите от търсенето с Google и подобрения.“
Google: Продуктови страници на единствени по рода си продукти, които не са в наличност, трябва да бъдат архивирани
Виждали сме как Google дава официални съвети за това как да се справите с продуктите, които не са налични на вашия уеб сайт. Но какво да кажем за продуктите, които продавате, които са единствени по рода си, направени уникални, направени веднъж и продадени на един човек?
Първо, официалният съвет идва от Мат Кътс през 2014 г., където той каза:
- Наистина малките сайтове могат да показват сродни продукти на продуктова страница, която е на склад
Среден сайт трябва да подаде 404 на страницата на продукта, който няма наличност или ако временно е в наличност, комуникирайте, когато се върне
Огромните сайтове трябва да използват мета таг unavailable_after, за да автоматизират този процес, когато знаете, че продуктът ще изчезне
Съвета на Джон Мюлер е преместването на тези страници в някакъв архив, където потребителският интерфейс се променя и вече не показва типа страница на продукта за покупка.
Връзка към Google Cache не зависи от трафика на сайта
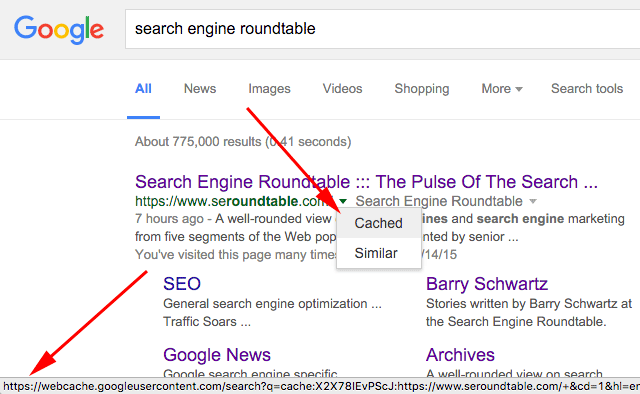
Джон Мюлер от Google беше попитан дали сайтовете с по-голям трафик имат по-голяма вероятност да получат кеш връзка в Google Търсене. Отговорът, който Джон Мюлер даде в Twitter, беше отрицателен, „нашето кеширане в търсенето не зависи от трафика“, каза той.
Повечето, но не всички сайтове го имат. Използваше се навремето, за да се види какво Google индексира дадена страница, липсва ли съдържание, вижда ли хакнато съдържание и т.н. Но сега наистина трябва да използвате инструмента за проверка на URL адреси в Search Console. Това ви дава най-точното представяне на това, което Google Search наистина вижда на вашата страница.
Кешът наистина не е показателен по отношение на ефективността ви в Google Търсене, дори и датата на обхождане.
Google тества въртележки /carousels/ за кратки видеоклипове в резултатите от търсенето
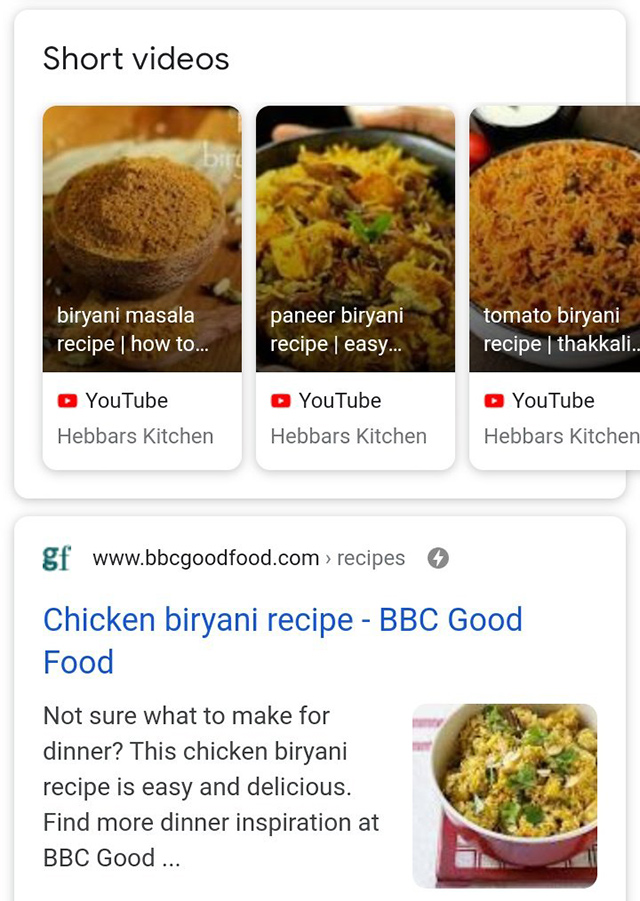
Google изглежда тества друга форма на въртележка в резултатите от търсенето с Google. Този се нарича „кратки видеоклипове“ и е забелязан за търсене в рецепти от Saad AK в Twitter.
Google Search Console подаде погрешно класифицирани данни за Discover като данни за ефективността на видео
Google е документирал, че на 28 октомври 2020 г. в някои случаи е класифицирал неправилно някои данни на Google Discover като видео в отчета за ефективността, след като е бил коригиран. Това може да доведе до „спад в статистическите данни за появата на видеоклипове във вашия отчет“, каза Google.
Google: Началната страница надминава вътрешните страници за long-tail ключови думи
Джон Мюлер от Google беше попитан защо Google понякога класира начална страница за конкретна ключова фраза, когато в сайта има по-дълбока страница, която отговаря по-добре на тази заявка. Началната страница е по-обща и обхваща по-широка тема, но има по-конкретна страница, която да отговори по-добре на заявката от началната страница. Защо Google не класира по-добрата страница за заявката?
Джон отговори на това в Twitter, казвайки, че „обикновено това е знак, че началната ви страница е значително по-силна в рамките на вашия уебсайт.“ Смисъл, може би по-дълбоката страница просто няма достатъчно сигнали, т.е. PageRank и / или други сигнали, за да се класира по-дълбоката вътрешна страница.
Джон каза, че понякога това може да се промени с течение на времето, той каза, че „понякога това е въпрос на време, тъй като хората откриват подробната ви страница и я препоръчват)“ Но той каза, че „понякога става въпрос и за това да сте супер ясни в рамките на вашия сайт“.
Google: Две различни Canonicals на една и съща страница се определят от Google като недефиниран canonical
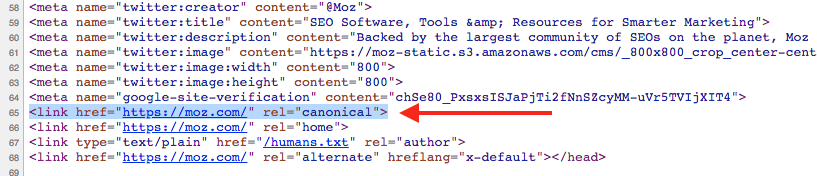
Какво се случва, ако имате два различни канонични URL адреса, изброени на една и съща страница, но знаете, че те сочат към различни URL адреси. Джон Мюлер от Google заяви в Twitter, че води до неопределеност на каноничната информация. Така че, Google ще използва други сигнали, за да определи каноничния URL, ако е необходимо.
Джон определи това като недефинирано. Джон добави „също така, rel-canonical не е директива, а само един от сигналите, които се вливат в процеса на каноникализация.“
Видео посветено на Google Search Quality Raters
Всяка година Google провежда стотици хиляди тестове, за да види дали промените, които обмисля, преди да въведе нещо, всъщност ще направят Google по-добър за хората, които го използват. Един от основните начини за тестване е чрез реални хора. Те се наричат оценители на качеството на търсене. Има над 10 000 от тях по целия свят и макар че длъжността звучи просто, това, което правят, всъщност е доста трудна работа.
По думи на Google: „Започва с нашите насоки за оценка на качеството на търсене, публично достъпно ръководство, което всеки читател изучава и е тестван, преди да предостави оценки. Това дава на читателите ясни насоки за това как да оценят неща като релевантност, надеждност и опит. Тогава, когато обмисляме промяна в търсенето, ние молим голям брой читатели да прегледат всеки стотици до хиляди търсения.
За всяко търсене читателите виждат резултати от две версии на Google и след това отварят всяка изброена връзка, за да предоставят оценка за качество за всяка. Тъй като от нападателите се изисква да дават оценки въз основа на общи насоки, без лични мнения и убеждения, процесът на оценяване изисква много допълнителни изследвания. Като кой е автор и ако други уважавани източници ги разглеждат като авторитети.
Въпреки че, задачата на читателя е да даде оценка на всяка страница, която вижда, този рейтинг не влияе пряко как ще се класира тази страница при търсения в реалния свят. Вместо това разглеждаме всички оценки на всички читатели в широк кръг от търсения, за да видим коя версия на Google постоянно дава най-високо качество и най-полезни резултати.
Само през миналата година проведохме над 380 000 теста за качество на търсенето, плюс близо 63 000 с нашите оценители за качество на търсенето, което доведе до над 3600 подобрения на нашите алгоритми за търсене. И въпреки че резултатите от търсенето ни винаги могат да се подобрят, този процес е много ефективен през последните 20 години и ни помага да гарантираме, че промените, които правим, отговарят на стандартите за качество, коeто хората навсякъде очакват от Google.“
Google: XML Sitemap основно изискване за всеки сериозен уебсайт
Джон Мюлер от Google заяви в Twitter, че наличието на XML файл на Sitemap е „основно изискване за всеки сериозен уебсайт“. По принцип всички сериозни уебсайтове трябва да имат XML файл със Sitemap част от него или това не е сериозен уебсайт.
Google: Няма планове за отнемане на инструмента за индексиране на заявки
Джон Мюлер заяви, че Google няма планове за премахване на тази функция, но ако може да обработва автоматично повече от направените в инструмента заявки, това ще спести на всички време. Ето защо той публикува проучване в Twitter, за да разбере какво трябва да прави Google там по различен начин. Джон обясни, че голяма част от обратната връзка, която са получили, е, че отнема няколко седмици, докато Google индексира страницата, ако не е изпратена ръчно, и каза, че това не трябва да е така. Той се надява тези примери да послужат за подобряване на системите на Google.
Актуализация на Google Page Experience за стартиране през май 2021 г. с нови етикети на фрагменти
Google обяви, че актуализацията на page experience ще бъде активна след около 6 месеца, т.е. през май 2021 г. С това стартиране Google също ще тества нови визуални индикатори, като етикети, в резултатите от търсенето, за да покаже на потребителите, ако тази страница се справя добре с основните показатели на уеб жизнените показатели.
Тази актуализация page experience включва метрики, много от които Google вече разглежда, включително скорост на страниците, удобство за мобилни устройства, безопасно сърфиране, HTTPS, натрапчиви interstitials, а сега и промени в оформлението. Скоростта на страницата и промяната в кумулативното оформление сега идват от „Core Web Vitals“, за които обхващахме много тази седмица.
Ето как Google може да използва machine learning по време на обхождане
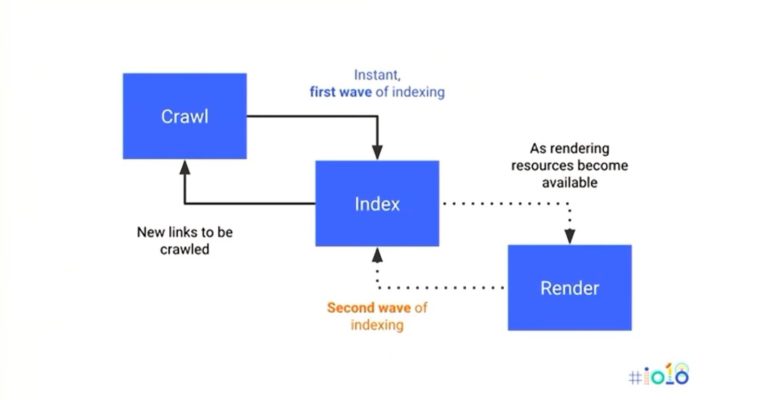
Мартин Сплит от Google каза, че Google може да използва машинно обучение – mаchine learning при обхождане или може да е просто експеримент, но ето как използва машинното обучение за обхождане в търсене. Трябва да отбележа, че доколкото е наясно, машинното обучение не се използва за rendering в Google Търсене.
Мартин каза, че вярва, че Google използва Machine Learning за обхождане, но не и за рендиране. Как Google използва машинно обучение за обхождане? Два начина за прогнозиране на качеството на URL адреса, преди Google да го обходи и за прогнозиране на свежестта на URL адреса, преди Google да го обходи.
Прогнозиране на качеството
„Знам, че използваме машинно обучение, за да идентифицираме или да предскажем какво ще получим от обхождането по отношение на качеството“, каза Мартин Сплит от Google. Той каза, че е интересно да се опитаме да „предскажем какъв вид качество можем да получим от конкретно обхождане, преди да се случи“. Той каза, че причината за това е, защото това ще позволи на Google да „планира обхождането по-интелигентно“.
Ако Google се притеснява да използва ресурси за обхождане на URL адрес, които може да не си струват времето, тъй като страницата не е достатъчно качествена, за да гарантира, че това е въпросът, който ML се опитва да отговори.
Предсказване на свежестта
Мартин Сплит каза: „същото важи и за това, ако можем да предскажем свежест, тъй като знаем, че трябва да планираме този уебсайт ежедневно, можем ли да събираме сигнали, които да ни казват да не правим това ежедневно.“
Така че Google може да използва машинно обучение, за да прогнозира това за сайтове, за които Google няма толкова много данни, т.е. данни за честотата на промяна на съдържанието. Той поясни „но не съм сигурен дали използваме това в в действителност или експеримент засега.“
Google: Пренасочените URL адреси са поставени в клъстер за каноникализация
Джон Мюлер от Google обясни как Google обработва пренасочванията в своя индекс. Той сподели, че Google „поставя (URL адресите) в споделен клъстер, който след това използва за каноникализиране“.
След като са в този споделен клъстер, Google преминава през процеса на откриване на избор на каноничния. Сигналите, които Google използва за това, както разгледахме по-рано, включват не само дали има пренасочване, но и „вътрешните връзки във вашия уебсайт, външни връзки, сайтмап на сайта, други анотации, които имате на тези страници“, каза Джон. Имайте предвид, че Google не присвоява тежести на тези сигнали ръчно, машинното обучение се справя с това, както каза Gary Illyes.
Накратко, искате да бъдете възможно най-ясни и последователни с всички тези сигнали. По този начин Google знае кой URL искате да бъде каноничният URL адрес. Така че, ако имате 301 пренасочване от URL A към URL B, но има канонична връзка обратно от URL B към URL A, това не е последователен сигнал. Подобни неща се случват и ще се случват много в интернет. Така че Google използва много сигнали, за да се опита да разбере кой URL трябва да бъде каноничният.
Това не е проблем с класирането, защото един от URL адресите ще се класира – въпросът е дали URL адресът, който искате да класирате.
GoogleBot сега може да обхожда HTTP / 2
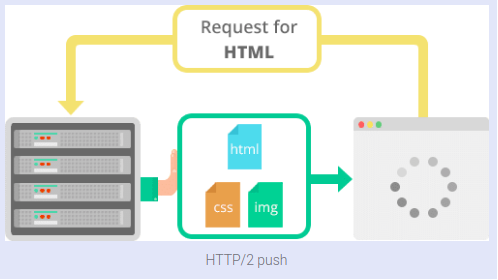
Миналия месец Google ни каза, че от ноември GoogleBot ще поддържа обхождане на сайтове през HTTP / 2. Е, това време дойде и ако видите, че това се случва, това е така, защото Google смята, че може да спести изчислителни ресурси за обхождането на вашия сайт по този начин.
Като цяло Googlebot обхожда HTTP / 1.1. От ноември 2020 г. обаче Googlebot може да обхожда сайтове чрез HTTP / 2, ако това се поддържа от сайта. Това може да спести изчислителни ресурси (например CPU, RAM) за сайта и Googlebot, но това не засяга индексирането или класирането на вашия сайт.
Google споделя бюджета за обхождане между органични и реклами
Google споделя същия бюджет за обхождане между Googlebot, органичния безплатен уеб робот и Google AdsBot, платения робот на Google. Имайте предвид, че Google има десетки роботи и всички те вероятно споделят един и същ бюджет за обхождане.
Джон Мюлер не каза ясно да или не. Това, което той каза в Twitter, беше „Целта е да се предотврати обхождането да премахне сървъра, така че трябва да преброите всички заявки, независимо от типа на обхождането. Това не е нещо ново. Също така статистиката за обхождане показва комбинирани заявки.“
Google Disavow Tool мигрира към нова конзола за търсене
Google мигрира старата версия на инструмента за отказ от връзки към новата версия на Google Search Console. С това Google направи формата по-хубава, добави възможността за изтегляне на файла като текст и добави още грешки към отчетите за грешки за качени файлове.
Google: Индексирането на пасажи е спасително средство за страници с разредено съдържание
Мартин Сплит от Google сподели, че индексирането на пасажи наистина е спасително средство за страници, които имат добро съдържание, но е заровено или разпръснато на голяма страница. Индексирането на пасажа е за Google да разбере по-добре тези лошо проектирани или структурирани страници.
Google знае, когато ъпгрейднете сървъра си и ще научи колко бързо и често да обхожда
Когато премествате уебсайта си от един хост на друг, Google обикновено знае за него. Когато Google открие промяната, той може и вероятно се опитва да се научи колко бързо и често трябва да обхожда вашия сайт. Гари Илиес от Google каза това в Twitter наскоро.
Той сподели: „Забавен факт: промяната на основната инфраструктура на даден сайт, като сървъри, IP адреси, може да промени колко бързо и често Googlebot обхожда споменатия сайт. Това е така, защото всъщност открива, че нещо се е променило, което го кара да се научи колко бързо и често може да обхожда.“
Google: Други уебсайтове, копиращи вашето съдържание, няма да бъдат причина за по-ниско класиране на вашите страници
Джон Мюлер от Google заяви в Twitter, че само защото някой копира съдържанието ви, това не означава, че страниците ви ще се класират по-ниско в Google Търсене. Той каза, че „другите, които копират вашето съдържание, не биха били причина страниците ви да се класират по-ниско“.
Google: Не можете да принудите GoogleBot да ви обходи през HTTP / 2
Както знаете, Google започна да обхожда някои сайтове през HTTP / 2 този месец. Въпреки че можете да се откажете от това, т.е. GoogleBot да обхожда вашия сайт през HTTP / 2, не можете да се включите в него, поне не сега. Джон Мюлер от Google заяви в Twitter „ние не избираме ръчно сайтове за подобни изпитания, по-скоро става въпрос за това дали е възможно и има смисъл за обхождане“.
Той също така добави, че няма подобрение в класирането за обхождане през HTTP / 2. В краткосрочен план, ако не искате Google да обхожда вашия сайт през HTTP / 2, инструктирайте сървъра, който хоства вашия сайт, да отговори с код на състоянието 421 HTTP, когато Googlebot се опитва да обходи вашия сайт през HTTP / 2. Ако това не е възможно, можете да изпратите съобщение до екипа на Googlebot (обаче това решение е временно).
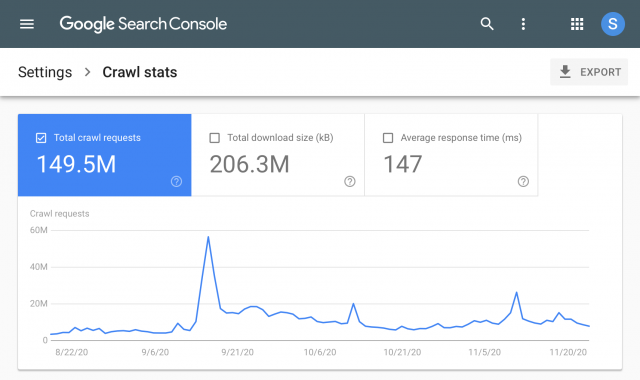
Отчетът за статистически данни за обхождането на Google Search Console вече е изключителен
Google обяви стартирането на новия доклад за статистически данни за обхождане и, честно казано, това е огромно надграждане от предишния доклад. Този отчет сега ви дава данни, които можете да използвате за отстраняване на грешки при обхождане и проверка на състоянието на вашия сайт с проблеми, свързани с обхождането в Google Търсене. Новите отчети наистина ви позволяват да се потопите в повече детайли и ви дават общия брой заявки, групирани по код на отговор, тип обходен файл, цел на обхождане и тип на Googlebot. Той ви дава подробна информация за състоянието на хоста, примери за URL адреси, за да покажете къде са възникнали заявките на вашия сайт и изчерпателно резюме за свойства с множество хостове и поддръжка за свойства на домейн.
Google: Данните за домейн Whois не оказват влияние върху класирането
Джон Мюлер от Google заяви, че наличието на частен статус за регистрация на имена на домейни в Whois не променя начина, по който Google се доверява на сайта. Това наистина не оказва влияние върху класирането на сайта в Google Търсене.
Google: Все още можем да класираме страница, след като съответстващото съдържание бъде премахнато
Да приемем, че името на вашата компания е Google и след 17 години (и 28 дни) решавате да промените името си на Азбука – просто теоретична промяна на името. Така че премахвате Google от цялата си начална страница и я променяте на Азбука. Знаете ли, че началната страница все още може да се класира за думата [Google], дори ако сте премахнали това от страницата си?
Джон Мюлер от Google заяви, че Google все още може да класира страница за конкретна ключова дума, дори ако премахнете тази конкретна фраза или дума от страницата си. Джон каза в Twitter „Ако знаем, че текстът е бил на дадена страница, може да продължим да показваме страницата, дори ако текстът е бил премахнат.“ Джон даде пример, „ако дадена компания промени името си, все пак ще искате да намерите уебсайта, ако сте търсили старото име“.
Google: По-дългият анкор текст не е по-добър, но може да осигури повече контекст
В петък Джон Мюлер от Google беше попитан дали по-дългият анкор текст е по-добър. Джон каза, че по-дългият или по-краткият котва текст не е по-добър или по-лош, той просто дава на Google повече или по-малко контекст за страницата, към която води връзка. По думи на Джон: „Не мисля, че правим нещо специално за дължината на думите в анкор текста.“ Той добави, че Google използва „този анкор текст като начин да предостави допълнителен контекст за отделните страници“. „И понякога, ако имате по-дълъг котва текст, това ни дава малко повече информация. И това е нещо, където, особено за вътрешно свързване, искате да се съсредоточите повече върху неща като как можете да направите по-ясно за потребителите си, че когато щракнат върху тази връзка, ще намерят каквото търсят. Google казва, че думите около вашия котва текст са вторични по отношение на тежестта спрямо самия анкор текст.
„Не бих казал, че по-краткият анкор текст е по-добър или по-краткият котва е по-лош. Това е просто различен контекст. „
Текстът на котва е бил използван в миналото, за да помогне на страницата да се класира за ключовите думи, към които е насочена. Така че, ако искам тази страница да се класира добре за [дълъг котва текст], бих направил връзка към тази страница от други страници с думите дълъг котва текст (разбира се, вътрешният котва текст срещу външен котва текст също влиза в игра). Това е фактор за класиране, поради което човекът пита дали има значение дълъг или по-кратък котва текст, защото понякога може да е твърде дълъг и контекстът да се загуби.

Anchor тексът е фактор за класиране в Google
Като цяло, когато става въпрос за връзки, това, което се опитваме да разгледаме, е конкретният им анкор текст. Така че, ако в него има нещо, което популяризира този уебсайт по начин, който използва много богат на ключови думи текст, тогава това би било проблематично. Ако по същество това е просто връзка към URL адреса или ако използва името на бизнеса като нещо, което се свързва с името на уебсайта, обикновено това е по-малък проблем.





