Обзор на Google – Октомври 2021

Google казва, че случаят с URL адреси се отнася до директивите robots.txt
Преди всичко е важно да напомним, че Google може да третира един и същ URL адрес при различните случаи различно. Така, например, домейн.com/Apple и домейн.com/apple могат да се разглеждат от Google като различни URL адреси. Но, когато става въпрос за robots.txt, то Google се отнася по-строго към това правило.
В случая с домейн.com/Apple и домейн.com/apple Google може да разбере дали страниците са идентични, като ще канонизира URL адрес към една от тях. Това означава, че при търсене в Google ще се показва само едната от тях.
John Mueller сподели, че именно в robots.txt точният URL адрес играе важна роля. В този файл вие можете да сигнализирате кои части от вашия уебсайт не трябва да се обхождат. Той добави, че в robots.txt трябва да се използват точни URL адреси, така че ако имате записи в него, които се отнасят за една версия на даден URL, те няма да се отнасят за други версии на този същия URL адрес.
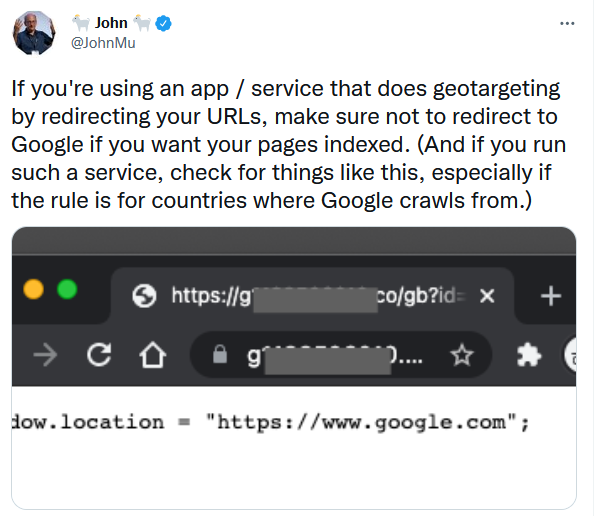
Google: Когато пренасочвате с цел геотаргетиране, не пренасочвайте Googlebot
John Mueller от Google публикува съобщение в Twitter, в което казва, че не трябва да пренасочвате Googlebot, когато използвате техники за пренасочване с цел геотаргетиране. Трябва да бъдете внимателни в това, тъй като може да доведе до проблеми с индексирането.
Как Google Search се справи с прекъсването на работата на Facebook?
Както знаем, в началото на октомври Facebook спря да работи за няколко часа. Това доведе до огромни загуби на компанията и до много неудобства за потребителите от гледна точка на комуникацията в WhatsApp, Facebook и Instagram. Но как това се отрази в търсачката на Google – как се справи Google от гледна точка на класиране, индексиране и обхождане?
В Twitter John Mueller сподели документация относно това как Google се справя с такъв тип прекъсвания на сайта. Накратко, прекъсване работата на сайта за няколко часа не води до проблеми с класирането в дългосрочен план.
Необходимо е да минат няколко дни, за да може Google да премахне страниците от индекса. Търсачката е наясно, че сайтовете имат такива прекъсвания, затова им дава някакво време да се справят с проблема.
Google: Всичко в SEO се отнася до това да не изисквате от търсачките да четат вашите мисли
Точно това написа John Mueller в Twitter, което е напомняне за това, че собствениците на сайтове и SEO специалистите трябва да направят така, че да не объркват Google. Използването на правилните атрибути и тагове и създаването на ясна структура са малка част от нещата, които ще помогнат на Google да разбере по-добре вашия сайт.
Отчетите за състоянието на богатите резултати в Google Search Console се сдобиват с повече грешки, които могат да бъдат използвани
Google обяви в Twitter, че добавят повече детайли към някои грешки в отчетите за състоянието на богатите резултати в Google Search Console, като целта е да ги направят по-приложими и да помогнат на специалистите и собствениците на сайтове да разрешат тези проблеми.
Google: Google Merchant Center позволява един фийд за всички държави
Google обяви, че прави промяна, която ще опрости показването на вашите продукти за всички държави. До момента Merchant Center позволяваше продуктите да се показват в една от две групи държави. Промяната цели да обедини всички групи държави в един глобален списък, позволявайки ви по-лесно да показвате вашите продукти във всички поддържани държави.
Два нови помощни документа на Google относно това как да създавате заглавия и мета описания с нов title link
Google представи два нови помощни документа относно създаването на заглавия и описания при търсене в Google. По-голямата част от съдържанието в документацията не е ново, но има добавена полезна информация, включително и определението на Google за title link, който го определя като линк, върху който може да се клика в резултатите от търсенето. Документите са на темите:
- Как да напишете title tags за SEO?
- Как да напишете мета описания?
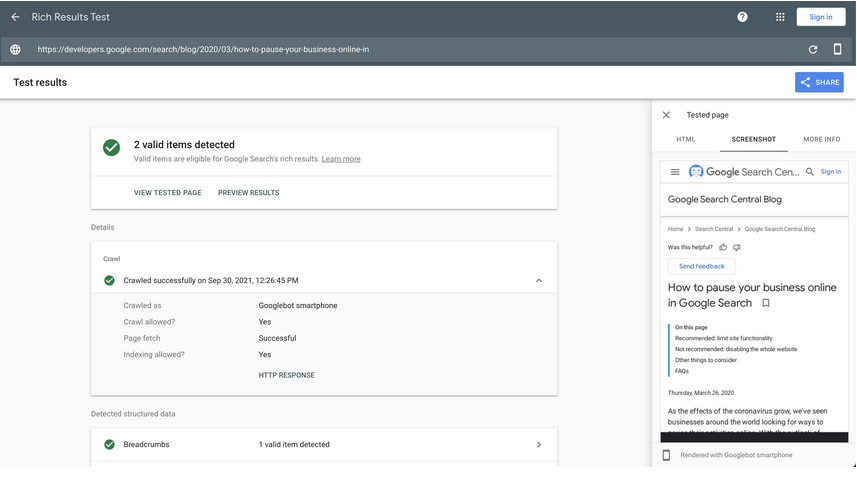
Google отговаря на обходените грешки, които не са индексирани, като казва, че това е просто закъснение
В Twitter Google сподели, че няколко потребителя на Google Search Console са забелязали, че в Index Coverage отчета има URL адреси, които са със статус “Crawled – currently not indexed”. Съответно при проверка с URL Inspection tool тези URL адреси са отбелязани като “Submitted and indexed” или друг статус.
Google обясни, че една от причините за това е, че данните от Index Coverage отчета се обновяват с различна (по-бавна) скорост от тези на URL Inspection. Когато има разминаване в двата отчета, трябва да се вземе предвид URL Inspection, тъй като данните са по-нови и достоверни.
Инструментите в Google Search Console започват да съответстват с инструмента URL Inspection
Google актуализира три от своите инструмента в Google Search Console, така че да съответстват на инструмента URL Inspection. Това са AMP, Mobile Friendly и Rich Results, като те вече са визуално и функционално сходни с инструмента URL Inspection.
Google добави, че промените включват стандартизиране на предишни функции и добавяне на нови функции, които може да са ви познати от URL Inspection. От тук насетне следните полета ще бъдат отчитани както в трите инструмента на Google Search Console, така и в инструмента URL Inspection, а именно:
- Наличност на страницата – дали Google е обходил страницата, кога я е обходил или пречки, които Google е срещнал по време на обхождането;
- HTTP header – отговорът на HTTP header, върнат от инспектирания URL адрес;
- Скрийншот на страницата – визуализираната страница, както я вижда Google;
- Сдвоена проверка на AMP – инспектиране както на каноничния и AMP URL.
Google не класира популярни WordPress теми по-ниско
В Twitter имаше въпрос към John Mueller за това дали използването на много популярни WordPress теми може да окаже негативно влияние от гледна точка на класиране при търсене и SEO оптимизация. В отговор John каза, че популярността на темата не оказва никакво влияние върху SEO.
Грешките в богатите резултати на Google за обяви за работа могат да се увеличат поради промени в оценката
Google съобщи, че има промени в Google Search Console относно начина, по който оценява и съобщава за грешки в структурираните данни на обявите за работа. Съответно могат да се наблюдава увеличение на проблемите, както и промяна в сериозността на някои проблеми, т.е. от статус errors към статус warnings.
Performance отчетът на Google е актуализиран за филтъра News и Page Experience
Още през септември Google предупреди, че може да се наблюдава увеличение на броя на кликовете и импресиите за Good Page Experience search appearance за филтъра за тип на търсене “News”. Това се дължи на промяната в логването, като Google допълни, че тази промяна няма да рефлектира на промяната в потребителското поведение или резултатите от търсене. Тя засяга само промяната в регистрирането в Search Console.
Google: Видеоигрите не са валидни типове софтуер за Software App Schema
Google уточни в своята документация за Software Application Schema, че VideoGame не е валиден за софтуерни приложения. В случай, че искате да използвате конкретно VideoGame, то трябва да включите още един поддържан тип за вашите структурирани данни. Това, което поясни Google, е, че не показва богат резултат за софтуерни приложения, които имат само типа VideoGame. Необходимо е да добавите и друг тип софтуер, който е съвместим с VideoGame, за да сте сигурни, че вашето софтуерно приложение отговаря на условията за показване като богат резултат.

Името на автора в Google Reviews снипетите трябва да бъде по-малко от 100 символа
Google актуализира указанията си за структурираните данни за reviews snippets, като посочи, че името на автора трябва да бъде по-малко от 100 символа. В случай, че е по-дълго от 100 символа, то страницата ви няма да отговаря на условията за авторски отзив.
Анотация на централния елемент на Google: Основно съдържание на страницата и сайта
На уебинара Duda Martin Splitt от Google обясни концепцията Centerpiece Annotation, която разглежда начина, по който Google анализира съдържанието на дадена уеб страница. Той обясни това как Google отделя шаблона на уебстраницата и след това обобщава от структурата на текстовото съдържание за какво се отнася самата уеб страница.
След това допълни как при анализа на съответната уеб страница тя се разделя на съставни части, като някои от тях не са релевантни за centerpiece annotation. Мартин обясни, че частите на страницата се притеглят по различен начин и се определя колко важен е даден елемент на страницата.
Съдържанието с различно намерение (intent) може да обърка на ниво страница, а не на ниво сайт
На втората за месец октомври Google SEO office-hours hangout имаше въпрос към John Mueller от Google, който се отнасяше за сайт за електронна търговия, в който има и информационен блог. Въпросът бе дали Google би могъл да се обърка и да си помисли, че сайтът е за информационна заявка, а не за транзакционна.
В отговор John Mueller каза, че когато става въпрос за объркване на Google със съдържание с различно намерение, то по-скоро става въпрос за проблем на ниво страница, а не на ниво сайт.
Той допълни, че “повечето сайтове са микс от различно съдържание. Когато се опитате да разберете коя от тези страници отговаря на намерението на потребителя, който търси, съответно се опитвате да класирате тези страници. Затова по-скоро си мисля, че това е на ниво страница, а не на ниво сайт.”
Google актуализира указанията за Search Quality Raters
След като повече от една година нямаше актуализация в указанията за Search Quality Raters, то Google направи няколко този месец. Това, което Google е променил в документа, е:
- разширено е определението на подкатегорията YMYL “Групи от хора”;
- обновени са указанията за това как да проучвате информация за репутацията на сайтове и създателите на съдържание;
- преструктурирана и актуализирана е секцията Lowest Page Quality;
- опростено е определението за Upsetting-Offensive и други.
Google: <Buttons> не са линкове, те не се използват за целите на обхождане
В Twitter имаше въпрос, отправен към John Mueller, в който се питаше дали атрибутът <button> се третира като атрибута <a href>. Накратко John отговори с не и допълни, че button-атрибутите не са линкове и те нямат прикрепени URL-и, съответно Google не ги използва за обхождане.
Google: Няма SEO полза за отваряне на линкове в съществуващи или нови прозорци
John Mueller беше попитан дали отварянето на линкове в нов прозорец в браузера в сравнение с отварянето на линка в същия таб би имало някакво значение от гледна точка на SEO оптимизация и класиране при търсене в Google. John отговори, че за целите на класирането няма никаква разлика.
Google: Авторът не е директен фактор за класиране
На въпроса “има ли значение дали признат или авторитетен лекар е написал или прегледал медицинско съдържание, когато става въпрос за препоръките на Google относно E-A-T?”, John Mueller отговори, че авторът на статията не е директен фактор за класиране.
Google: Понякога Black Hat SEO практиките работят и понякога Google няма да ви хване, но. . .
В Twitter John Mueller призна, че понякога Black hat SEO практиките работят и не винаги Google ги хваща. Той добави, че понякога можете да бъдете и хванати, а ако не сте, не означава, че тези рискови практики ще работят добре за вас. В заключение каза, че използването на подобни практики за изграждане на бизнес “изглежда ужасна идея”.
Google: Доверието не е само въпрос на линкове
“Дали уебсайт, който включва голямо съдържание подобрява доверието на Google или се определя само чрез линковете?” – това беше един от въпросите към John Mueller на една от октомврийски петъчни SEO срещи.
В отговор John заяви, че когато става въпрос за изграждане на доверие, то определено не е само до линковете, които сочат към даден сайт. Той каза, че доверието не е нещо, за което Google има оценка.
Google: Не класифицираме сайтовете по технологична платформа или инфраструктура
John Mueller сподели, че търсачката не класифицира вида на сайта въз основа на технологичната платформа или инфраструктура, която той използва. Той допълни, че Google определя какво е намерението на сайта според това какво е съдържанието на страницата и начина, по който тази страница е структурирана. Но Google не се базира на инфраструктурата, която използвате.
Добре идея ли е в статия да използваме просто “admin” или “автор” вместо името на автора?
Въпрос към John Mueller се отнасяше за сайт за ревюта на театрални новини и билети, като част от съдържанието, което се публикува в него, е по-общо и е от продуцентите на дадено шоу. В тази връзка специалистът, който управлява сайта, попита на една от петъчните SEO срещи дали е добре да се посочи admin за автор на статията или винаги трябва да стои човек с име зад автора.
John Mueller започна с това, че тези притеснения сред специалистите са резултат от всичко, свързано с информацията и наръчниците за оценка на качеството относно EAT, които Google публикава и по-конкретно за експертността, авторитета и доверието.
Той обясни, че това се отнася основно за сайтовете, които наистина са критични, каквито са тези с медицинска или финансова информация. В тези случаи със сигурност всеки потребител ще иска да е сигурен, че този, който е писал съдържанието, е някой, на който може да се вярва и е авторитет по темата.
Но при по-общ уебсайт за новини, ревюта и билети не би се притеснявал толкова много за автора. Той допълни, обаче, че да имаш администратор като автор, изглежда твърде общо и в този случай би било по-добре да няма автор или съдържанието да е написано от сайта. Като заключи, че това е въпрос на личен избор.
API на Google Search Console придобива данни за Discover и Google News с поддръжка на Regex
Google обяви, че е добавил данните за Discover и Google News и към API на Search Analytics. Google каза, че параметърът searchType, който преди е позволявал филтриране на API заявки по новини, видео, изображение и уеб, сега ще бъде преименуван на type и ще поддържа два допълнителни параметъра, а именно discover (за Google Discover) и googleNews (за Google News). Към това сподели, че докато преименуват параметъра, те ще поддържат старото име searchType.
Google: Не следим реда на линковете в дадена страница
Въпрос към John Mueller в Twitter се отнасяше до това кой линк Googlebot гледа първо в дадена страница – този, който е в Header или Footer? В отговор John каза, че не смята, че Google следи реда на линковете в съответната страница.
Google: Не се интересуваме от изображението за уеб търсене
John Mueller заяви, че когато става въпрос за уеб търсене, то Google не разглежда конкретни изображения на страницата за целите на уеб търсенето или класирането. Това го прави само когато се отнася за търсене на изображения. А въпросът, който се зададе на John, беше: Ще разбере ли алгоритъмът, че има смислено, може би дори и полезно изображение, а не просто “сив квадрат”?
Ограничено прилагане на UPI на продукти в Google Merchant Center
Google заяви, че от ноември 2021 година въвежда ограничено прилагане на UPI. В Обзор на Google за месец септември споделихме, че Google Merchant Center ще наложи всички продукти да имат уникален продуктов идентификатор (UPI). Напомняме, че уникалните продуктови идентификатори включват GTIN, MPN и марка.
Google каза, че преди това, когато при дадена продуктова обява липсваха задължителните атрибути, то продуктът беше отхвърлен и не се показваше в безплатните обяви. Сега, с въвеждането на ограниченото прилагане на представянето, продуктите, за които липсват атрибути, ще продължат да отговарят на условията, но тяхното представяне може да бъде органичено.
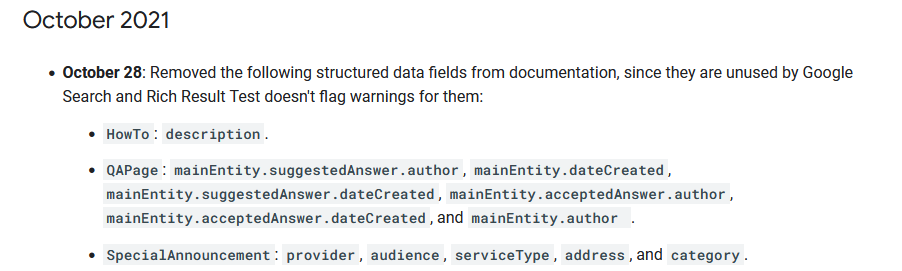
Google премахва някои HowTo, QAPage и SpecialAnnouncement от помощната документация
Google премахна някои полета за структурираните данни от помощната документация за търсене в Google. Това, което заяви, е, че те са премахнати, тъй като не се използват от Google Search и тестът за богати резултати не отбелязва предупреждения за тях. Ето и кои са те:
Google: Честото актуализиране на sitemap може и да е добра идея
На последната за месец октомври Google SEO office-hours hangout, John Mueller говори за това, че може би е добра идея да има отделен XML файл с sitemap за URL адресите, които често се актуализират. Той добави, че поставянето на по-нови URL адреси в “често актуализиран” sitemap файл вероятно е добра идея.
По тази тема имаше отправен въпрос към John и в Twitter, където потребител обясни следното: “sitemap с над 250 хиляди страници (многоезични страници), разделени в 18 XML файла…Всички XML файлове се актуализират често и в тях има страници с висок приоритет, но Google не ги чете толко често.”
Въпросът на потребителя бе: “Трябва ли да направя по-малко файлове? Или да събера всички важни страници заедно?” В отговор John каза, че поставянето на по-новите URL адрес в често актуализиран sitemap е добра идея. Той допълни, че ако всички 250 хиляди страници се актуализират редовно, то винаги ще е предизвикателство.
Google за това как да се намали дублиране с 10 пъти
John Mueller е написал интересен коментар в Reddit относно URL адресите и намаляване на дублирането. Той споделя, че начинът, по който са структурирани URL адресите на публикации в блог, например, няма да промени каквото и да било за обхождането, индексирането или класирането.
В случай, че се наблюдава проблем с обхождането, трябва да се намери вариант, при който да се намали дублирането с 10 пъти, а не да се фокусираме върху отделни URL адреси. В пример каза: “ако имате 100 хиляди продукта и всички те имат по 50 URL адреса, промяната от 5 милиона URL адреса на 500 хиляди ще си струва усилията.”
Google каза, че алгоритъмът Penguin може не само да игнорира линкове, но и да се насочи към целия сайт
На въпроса: “Дали наказанието на алгоритъма Penguin е все още актуално или по-малко релевантните/спамърски/токсични backlinks са повече или по-малко игнорирани от алгоритъма за класиране?”, John Mueller сподели, че в повечето случаи Google ще игнорира връзките, но когато има ясен модел на спам или манипулативни линкове от сайта, то Penguin може да загуби доверието си към този сайт и съответно да има спад на видимостта.






